算法-KMP
引言
大一下参加学校ACM预备队集训的时候首次接触KMP算法,当时看了很多介绍文章,仍然不是很理解其实质,只是简单地套模板AC题目,待大二数据结构与算法课堂上再听老师介绍一次,才恍然大悟其实KMP也就是那么回事嘛。但当初为啥看那么多文章都没弄明白呢?正巧最近和朋友聊天时他告诉我他对KMP不是很理解,于是打算自己写一篇文章,巩固自己对KMP的认识,也希望能够帮助更多朋友理解KMP。
在开始之前,需要知晓的概念:
前缀:以原串串头为自身串头的子串,如$abcdef$的前缀有:$a,ab,abc,abcd,abcde$
后缀:以原串串尾为自身串尾的子串,如$abcdef$的后缀有:$f,ef,def,cdef,bcdef$
注意:字符串前后缀都不包括该串本身
问题引入
给你一个文本串T(Text String)
1 | abcOabcXabcOabcYabcOabcZ |
再给你一个模式串P(Pattern String)
1 | abcOabcZ |
问该模式串是否在文本串中,怎么找?
一开始只好分别从文本串与模式串的串头开始逐字母比较
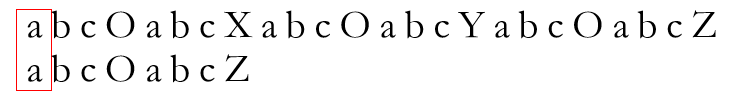
二者相同,再比较T串与P串的下一位
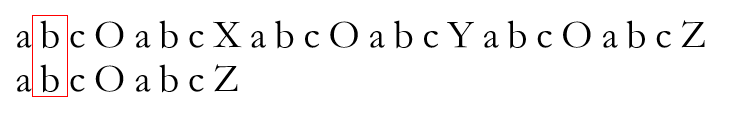
如此反复
如果一直这么顺利,两串对应位置的字符总相同,待P串中最后一个字符也匹配完毕,说明该模式串在文本串中存在,耶( •̀ ω •́ )y超开心,查找结束。但,大多数匹配过程不会如此顺利,在该例中,当匹配进行至
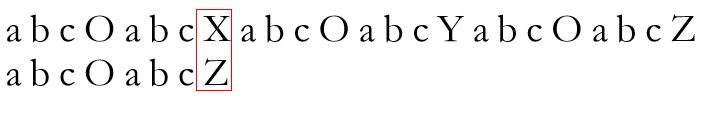
很明显,失配了。现在怎么办?按朴素思想,将P串相对T串整体右移一位,重新开始匹配,即
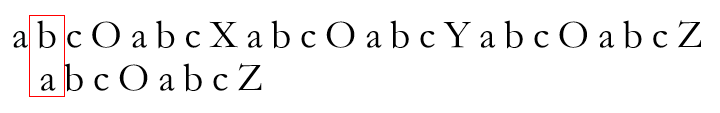
但这种算法效率无疑是十分低下的。设T串长度N,P串长度M,则朴素算法时间复杂度为O(MN)
已知的重要信息并没有被使用——已匹配的字符串前缀
在上例中,当P串最后一个字符匹配失败时,其已有包含七个字符的前缀子串S匹配成功
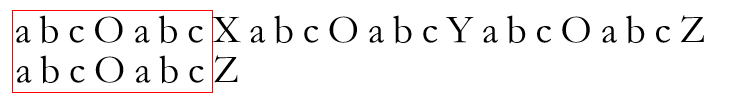
完全可以利用前缀子串S做点什么。观察到在S串
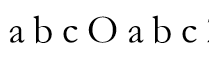
中,有相同前后缀,即下图蓝色部分
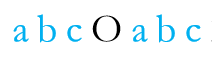
而S串各字符又与T串中对应字符相同,即有
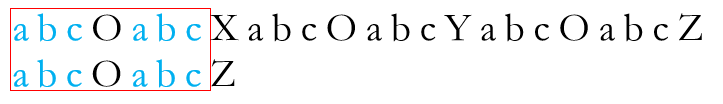
当失配发生后,直接将P串右移四位使S串蓝色后缀部分对齐T串中蓝色前缀部分
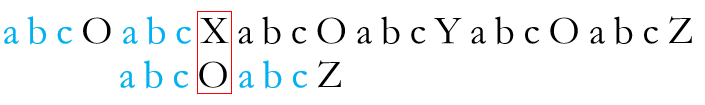
从图中红框部分继续尝试匹配,发现再次失配。这次,已匹配成功的前缀串S为
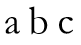
而在该串中没有相同的前后缀,只能将P串串头移至失配处进行比较
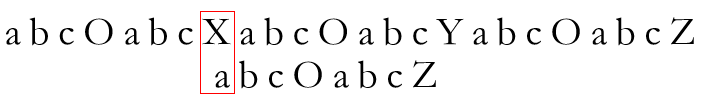
再次失配。此时前缀串S为空串,只好如朴素算法般将P串整体右移一位,重新开始比较
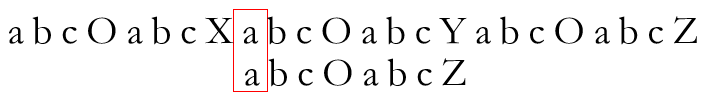
匹配成功。于是又按照之前的步骤往下匹配,直至再次失配或匹配成功
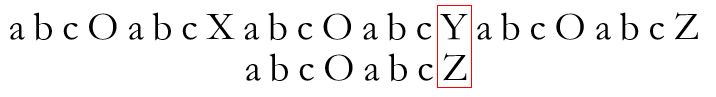
后续步骤同上,不再赘述
原理
上述示例已展现,KMP算法的精髓在于对已匹配成功的前缀串S的利用
在朴素算法中,匹配失败了,T串待匹配字符会回溯
T串原本已匹配至T[7] = ‘X’,但是因为失配,需回溯到T[1] = ‘b’重新开始匹配
而在KMP算法中,若P[M]与T[K]匹配失败,K不会回溯。既然匹配过程是从T[0]开始逐渐向右进行的,至T[K]失配发生时,T[0]至T[K-1]早已匹配过,何必再回溯过去重复匹配呢?于是乎,就如问题引入部分展示般
每当失配发生,我们总是去关注P串中已匹配成功的前缀串S
因为该前缀串是匹配成功的,说明在T串中必定存在与该前缀串相同的子串,记为S’
若S串中存在相同前后缀
则S’串必然也存在此相同前后缀
所以只需将P串右移四位,使得S串的该相同前缀对齐S’串的该相同后缀
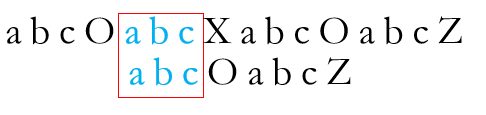
再尝试比较T[7]与P[3]
至于T[7]与P[3]是否能够匹配另说(当然,本例中一看就知道没匹配上),但通过对前缀串S的利用,成功省去了P串右移一位、两位和三位后的无效匹配
继续深入思考,给定一个具体的P串,其第N位的前缀串S内容是固定的,则S是否存在相同前后缀、相同前后缀的长度与内容也是确定的。换言之,对于一个具体的P串,当其与给定T串匹配至P[N]失配,P串应右移几位再次与T串进行匹配也是确定的。我们完全可以使用一个数组记录当P[N]失配后,应当使用N之前的哪一位再来与T串进行匹配,以此提高匹配效率,记该数组为Next数组
Next数组
定义Next[i] = j表示当P串中第i位失配后,跳转至P串第j位再次尝试匹配
还是以之前的P串为例,它的Next数组求出来应为
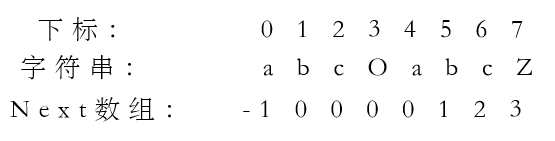
取下标5为例,其前缀串为
1 | abcOa |
最长相同前后缀为
1 | a |
若P[5]失配,应跳转至P[1]再次尝试匹配(最长相同前缀对应P[0],则取其后一位P[1],若存在多位,则取最后一位的下一位),P[5]的前一个字符P[4]对应字符’a’,而P[1]前一个字符P[0]同对应字符’a’,保证了P[1]之前字符与T串中对应字符保持匹配。所以Next[5] = 1,其余下标对应Next数组值同如此求。
特别地,规定Next[0] = -1。而对于除下标0外的任意下标N,Next[N]的含义是前N-1个已匹配成功的字符构成的前缀串S中,最长相同前后缀长度。所以若在下标为N处匹配失败了,则应前往Next[N]所对应的下标处匹配。
具体地,以下图所示为例,P[6]与T[6]失配
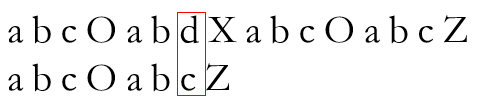
而Next[6] = 2,所以使用P[2]再次尝试与T[6]进行匹配
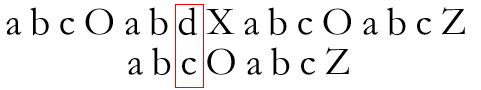
当求出P串Next数组后,便可快速进行与T串的匹配
1 | int KMP(char * t, char * p) //T为待匹配文本串,P为模式串 |
现在问题只剩下如何求Next数组,注意到Next数组既然只与P串本身相关,与文本串T无关,故令P串与自身匹配即可求得
1 | void getNext(char * p, int * Next) |
Next数组的优化
考虑字符串
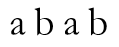
其Next数组应为

令其与给定文本串相匹配
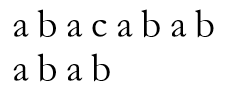
当匹配进行至
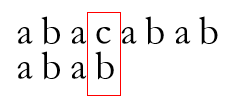
失配,于是跳转至P[Next[3]] = P[1]处再次尝试匹配
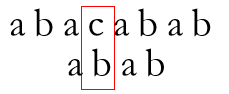
再度失配,也必然失配
问题在于不该出现P[N] =P[Next[N]]
若P[N] =P[Next[N]],则P[N]失配后使用P[Next[N]]再次尝试匹配,由于P[N] =P[Next[N]],P[N]匹配失败,P[Next[N]]必然也失败
因此,若出现P[N] =P[Next[N]]情况,则令Next[N]=Next[Next[N]]
1 | void getNext(char* p, int* Next) |
本例中该字符串新Next数组为

当匹配进行至
失配,于是跳转至P[Next[3]] = P[0]处再次尝试匹配
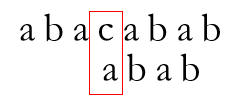
省去了之前跳转至P[1]处的无效匹配
总结
时间复杂度
设T串长度M,P串长度N,由于KMP算法不会回溯,分析易知时间复杂度为O(m+n)
为什么是最长相同前后缀?
对于P[N],若其前缀串S含相同前后缀F,且F长度为n(n>1),Next[N]可以取1至n中任意值,为最大化匹配效率考虑,总是取最大相同前后缀以提高效率,节省时间