主页
欢迎访问我的博客!
我计划于此分享有趣的东西,例如新学的知识、对某些问题的心得或是解决难题的思路等等。现在这个博客还很简陋,我会持续更新,将它做得更好,如果你想了解关于我的更多欢迎前往我的GitHub个人主页!
欢迎访问我的博客!
我计划于此分享有趣的东西,例如新学的知识、对某些问题的心得或是解决难题的思路等等。现在这个博客还很简陋,我会持续更新,将它做得更好,如果你想了解关于我的更多欢迎前往我的GitHub个人主页!
2048游戏项目源码阅读、学习、分析、复现
在C语言中,“数据”和“处理数据的操作(函数)”是分开来声明的,也就是说,语言本身并没有支持“数据和函数”之间的关联性。我们把这种程序方法称为程序性的(procedural),由一组“分布在各个以功能为导向的函数中”的算法所驱动,它们处理的是共同的外部数据。
如果我们声明一个struct Point3d,像这样:
1 | typedef struct point3d |
欲打印一个Point3d,可能得定义一个像这样的函数:
1 | void Point3d_print( const Point3d *pd ) |
在C++中,Point3d有可能采用独立的“抽象数据类型(abstract data type, ADT)来实现:
1 | class Point3d |
我们问:加了封装之后,布局成本增加了多少?答案是class Point3d并没有增加成本。三个data members直接内含在每一个class object之中,就像C struct的情况一样。而member function只会诞生一个函数实例。至于每一个“拥有零个或一个定义”的inline function则会在其每一个使用者(模块)身上产生一个函数实例。Point3d支持封装性质,这一点并未给它带来任何空间或执行器的不良后果。C++在布局以及存取时间上主要的额外负担是由virtual引起的,包括:
virtual function机制,用以支持一个有效率的“执行期绑定”(runtime binding)。
virtual base class,用以实现“多次出现在继承体系中的base class,有一个单一而被共享的实例”。
一般而言,并没有什么天生的理由说C++程序一定比其C兄弟庞大或迟缓。
在C++中,有两种class data members: static和nonstatic,以及三种class member functions: static、nonstatic和virtual。
在C++对象模型中,nonstatic data members被配置于每一个class object之内, static data members则被放在个别的class object之外。Static和nonstatic function members也被放在个别的class object之外,Virtual functions则以两个步骤支持之:
1.每个class产出一堆指向virtual functions的指针,放在表格之中,这个表格被称为virtual table。
2.每个class object被安插一个指针,指向相关的virtual table。vptr的setting和resetting都由每一个class的constructer、destructor和copy assigment运算符自动完成。每一个class所关联的type_info object(用以支持runtime type identification, RTTI)也经由virtual table被指出来,通常放在表格的第一个slot。
C++ Annotated Reference Manual(ARM)告诉我们:“default constructors……在需要的时候被编译器产生出来”。关键字眼是“在需要的时候”。被谁需要?答案是编译器需要。
C++ Standard说:对于class X,如果没有任何user-declared constructor,那么会有一个default constructor被隐式声明出来……一个被隐式声明出来的constructor将会是一个trivial constructor……
有4种情况,会造成“编译器必须为未声明constructor的classes合成一个default constructor”。C++ Standard把那些合成物称为implicit nontrivial default constructors。被合成出来的constructor只能满足编译器(而非程序)的需要。它之所以能够完成任务,是借着“调用member object或base class的default constructor”或是“为每一个object初始化其virtual function机制或virtual base class机制”而完成的。至于没有存在那4种情况而又没有声明任何constructor的classes,我们说它们拥有的是implicit trivial default constructors,它们实际上并不会被合成出来。
C++新手一般有两个常见的误解:
1.任何class如果没有定义default constructor,就会被合成出一个来。
2.编译器合成出来的default constructor会显示设定“class内每一个data member的默认值”。
如你所见,没有一个是真的!
在键盘上,按下<Return>键或^M键(它们等价)可以发送一个CR码。按下<Linefeed>或者^J键可以发送一个LF码。CR为返回信号,LF码为换行信号。
| erase | kill | werase | rprnt | flush | lnext |
|---|---|---|---|---|---|
| ^H | ^U | ^W | ^R | ^O | ^V |
| susp | intr | quit | stop | eof | |
| ^Z/^Y | ^C | ^\ | ^S/^Q | ^D |
erase删除最后一个键入的字符,werase删除最后一个键入的单词,而kill则删除整行。
| 字符 | 名称 | 作用 |
|---|---|---|
| {} | 花括号 | 花括号扩展:生成一种字符模式 |
| | | 管道 | 命令行:创建一个管道线 |
| < | 小于 | 命令行:重定向输入 |
| > | 大于 | 命令行:重定向输出 |
| () | 圆括号 | 命令行:在子shell中运行命令 |
| # | hash、pound | 命令行:注释的开头,忽略该行的其余部分 |
| ; | 分号 | 命令行:用于分隔多条命令 |
| ` | 反引号 | 命令行:命令替换 |
| ~ | 波浪号 | 文件名扩展:插入home目录的名称 |
| ? | 问号 | 文件名扩展:匹配任意一个字符 |
| [] | 方括号 | 文件名扩展:与一组字符中的字符匹配 |
| * | 星号 | 文件名扩展:匹配0个或多个字符 |
| ! | bang | 历史列表:事件标记 |
| & | 和号 | 作业控制:在后台运行命令 |
| \ | 反斜线 | 引用:下一个字符转义 |
| ‘ | 引号、单引号 | 引用:取消所有的替换 |
| “ | 双引号 | 引用:取消大部分替换 |
| {} | 花括号 | 变量:确定变量名称的界限 |
| $ | 美元符号 | 变量:用变量的值替换 |
| <Return> | 新行字符 | 空白符:标记一行结束 |
| <Tab> | 制表符 | 空白符:在命令行中分隔单词 |
| <Space> | 空格符 | 空白符:在命令行中分隔单词 |
有时候,可能希望按字面上的含义使用元字符,而不使用其特殊的含义。例如,将分号作为分号使用,而不是一个命令分隔符。或者可能希望不按管道使用|(竖线)。在这些情况中,必须告诉shell按字面意义解释字符。这样做时,可以称其为引用字符。
字符的引用方法有三种:使用反斜线、使用一对单引号或者使用一对双引号。
引用元字符最直接的方法就是在元字符前面放一个反斜线(\)。这就告诉shell忽略反斜线之后的字符的任何特殊含义。例如:
1 | echo It is warm and sunny\; come over and visit |
在这个例子中,我们在分号前放了一个反斜线。如果没有这个反斜线,那么shell将把这个分号解释成一个元字符,从而假定了您输入了两条独立的命令:echo和come。
考虑下述指令:
1 | echo It is warm (and sunny); come & visit |
这条命令不能正确运行,因为命令中有四个元字符。我们当然可以用四个反斜线依次引用每个元字符,但这样得到的命令却不容易阅读,一个更好的方法是使用单引号引用一串字符:
1 | echo 'It is warm (and sunny); come & visit' |
在这个例子中,我们将单引号之间的所有内容引用。当然,这包括所有的字符,而不仅仅是元字符,但是它不影响数字字母字符的显示。
大多数时候,反斜线和单引号引用已足够。但是,在有些情形中,使用双引号引用更加方便。有时候,可能希望在一个引用字符串中使用$字符,用来引用变量的值,例如,下述命令在尖括号中显示用户标识和终端类型:
1 | echo My userid is <$USER>; my terminal is <$TERM> |
这种形式的命令不能正常工作,因为元字符<、;和>拥有特殊的含义($字符没有什么问题,我们希望它是元字符)。解决方法就是只引用那些我们希望取字面含义的元字符:
1 | echo My userid is \<$USER\>\; my terminal is \<$TERM\> |
这条命令可行,但是它非常复杂。而如果使用单引号来取代反斜线:
1 | echo 'My userid is <$USER>; my terminal is <$TERM>' |
这样比较容易阅读,但它引用了所有的元字符,包括$。这意味着只能看到字面上的$USER和$TERM,而不能看到这两个变量的值。对于这种情况,可以使用双引号,因为这样所有的$元字符将保留它们特殊的含义。例如:
1 | echo "My userid is <$USER>; my terminal is <$TERM>" |
下面是小结:
使用反引号引用单个字符(称为转义了这个字符)。
使用单引号引用一串字符。
使用双引号引用一串字符。但是保留$(美元)、`(反引号)和\(反斜线)的特殊含义。
从前面的讨论中可以看出,单引号比双引号的功能更为强大。基于这一原因,有时候称单引号为强引用strong quote,双引号为弱引用weak quote。实际上,反斜线是所有引用中最强的一个。反斜线可以引用任何东西,因此,如果单引号不起作用,可以试一试反斜线。例如,有一天您可能需要转义一个单引号:
1 | echo Don\' t let gravity get you down |
反斜线功能如此强大,所以它甚至可以引用新行字符(花点时间好好想想这一点)。
假设在某行的末尾键入了\<Return>,这样将生成\字符后面跟新行字符。光标移动到下一行,但是由于新行字符失去了它特殊的含义,所以它并不是一行结束的信号。这意味着不管接下来键入什么字符都是上一行的继续。
1 | echo Tis is a very, very long \ |
su(substitute userid)命令允许您临时变成另一个用户标识。为此,只需在su命令后输入新的用户标识即可。
1 | [harley]$ su weedly |
当您结束weedly的工作时,您需要做的就是结束当前shell。输入exit命令就可以结束当前shell。一旦结束了新shell,您就会自动返回原来的shell,即用户标识harley。
1 | [weedly]$ exit |
上述例子中,您将用户标识变成weedly,但是仍然在harley的环境下工作。如果希望同时变换用户标识和环境,则需要在su命令名称之后键入一个-(连字符)。注意,连字符的两边都有一个空格。
1 | su - weedly |
现在您在weedly的环境中以weedly的名义工作了。
为方便起见,如果su命令没有指定用户标识,那么默认的用户标识是root。因此,下述两个命令是等效的。
1 | su - |
切换至超级用户的时间太长会非常危险,sudo(substitute the userid an do something)命令允许您以另一个用户标识执行一条单独的命令。和su命令一样,sudo命令的默认用户标识为root。因此,为了以超级用户执行一条具体的命令,只需:
1 | sudo command |
显示系统的键盘映射时,使用下述命令:
1 | stty -a |
stty是“set terminal”命令,-a意味着“显示所有的设置”。
| 信号 | 键 | 作用 |
|---|---|---|
| erase | Backspack / Delete | 删除键入的最后一个字符 |
| werase | ^W | 删除键入的最后一个单词 |
| kill | ^X/^U | 删除整行 |
| intr | ^C | 停止正在运行的程序 |
| quit | ^\ | 停止程序并保存core文件 |
| start | ^Q | 重新启动屏幕显示 |
| eof | ^D | 指示已经没有数据 |
如果希望修改键映射,只需键入stty,后面跟着信号的名称,然后是新的键赋值即可。例如,将kill键修改为^U的命令如下:
1 | stty kill ^U |
当在stty命令中使用带Ctrl的字符名时,不必键入大写字母。例如,下面两条命令都能正常工作:
1 | stty kill ^u |
查找某个程序是否可用的一种精确方法就是使用which命令,只需在键入的which命令后跟一个或多个程序的名称即可,例如:
1 | which date less vi harley |
我的机器运行以上指令的输出为:
1 | /usr/bin/date |
which没有找到名为harley的程序,因此没有任何输出
如果您使用的shell是Bash,那么which命令还有一个备用指令type,例如:
1 | type date |
如果使用的是Korn shell,那么您可以使用whence命令:
1 | whence date |
type和whence命令有时候要比which命令显示更多的细节信息。这在特定的环境下很有用。但是,在实机应用上,还是which命令的应用最广泛。
简单的输入:
1 | date |
Unix将显示当前的时间和日期。下面是一个样本输出,注意Unix使用的是24小时制时钟。
1 | Fri Dec 24 23:35:06 CST 2021 |
从本质上讲,Unix并没有运行在本地时间上。所有的Unix系统都使用协调世界时Coordinated Universal Time, UTC,它是格林威治标准时间Greenwich Mean Time, GMT的现代名称。Unix在需要时默默地在UTC和本地时区之间进行转换。本地时区的细节信息在安装Unix时指定。
有时候,查看UTC时间比较便利。为了显示UTC时间,只需使用:
1 | date -u |
显示当前月份的日历时,可以输入:
1 | cal |
显示某一年的日历时,需要指定年度。例如:
1 | cal 1949 |
为了显示某个特点月份的日历,需要先指定月份,再指定年度。例如,显示1952年12月的日历的命令如下:
1 | cal 12 1952 |
如果输入的是:
1 | cal 12 |
那么得到的是公元12年的日历。
如果不希望显示日期,只希望得到这一天是这一年中的第几天,只需在cal名称之后键入-j即可。
1 | cal -j 12 2009 |
uptime用来显示系统已经运行多长时间(也就是连续运行)的有关信息:
1 | uptime |
一些典型的输出:
1 | 11:10AM up 103 days, 6:13, 3 users, |
在这个例子中,系统已经运行了103天6小时13分钟,而且当前有3个用户标识登录。最后三个数字展现了一直等待执行的程序的数量,分别是之前1分钟、5分钟和15分钟的平均数。这些数字表示系统的负载。负载越高,系统所做的工作就越多。
hostname命令用来查看计算机的名称。如果经常登录不止一台计算机,那么该命令非常管用。如果忘记了正在使用的是哪一个系统,则可以输入:
1 | hostname |
uname命令显示操作系统的名称。
whoami命令显示您登录使用的用户标识。如果您突然得了健忘症,忘记了自己的名字,那么whoami命令也许特别有用。如果您的系统上没有whoami命令,则可以尝试输入下面3个单独的单词:
1 | who am i |
在计算机上工作时经常需要全神贯注,很容易忘记时间。为了帮助您及时完成其他事情,只需输入下述命令:
1 | leave |
leave将询问您一个时间:
1 | When do you have to leave? |
以hhmm(先是小时,后是分钟)的格式输入您希望离开的时间。例如希望在10:33离开,可以输入1033。
时间输入既可以是12小时制也可以是24小时制。例如,1344意味着1:44PM。而如果输入的小时数小于等于12,那么leave假定时间位于接下来12小时内。例如,如果现在时间是8:00PM,而您输入的是855,那么leave将它解释为8:55PM,而不是8:55AM。
如果需要在特定的时间间隔之后离开,则可以输入一个+(加号),后面跟着分钟数。例如,如果需要在15分钟之后离开,可以输入:
1 | leave +15 |
确保不要在+字符之后留空格。
如果您希望使用bc内置的数学函数库,那么在启动程序时需要使用-l(library)选项:
1 | bc -l |
不希望使用bc时,可以通过按^D或输入quit命令。
| 函数 | 含义 |
|---|---|
| sqrt(x) | x的平方根 |
| s(x) | x的正弦:其中x的单位是弧度 |
| c(x) | x的余弦:其中x的单位是弧度 |
| a(x) | x的反正切:其中x的单位是弧度 |
| ln(x) | x的自然对数 |
| j(n, x) | x的n次整阶贝塞尔函数 |
默认情况下,bc假定做整数运算。您可以设置一个标度因子,告诉bc您希望保留小数点后几位。例如,要保留小数点后面3位,可以输入:
1 | scale=3 |
如果希望查看标度因子的值,只需简单输入:
1 | scale |
bc允许设置并使用变量。变量由变量名和值组成。在bc中,变量名由一个小写字母构成。也就是说,bc中共有26个变量,从a到z(一定确保不要使用大写字母,当使用基时才使用它们——参见下面)。
您可以使用等号设置变量的值。例如,将变量x的值设置为100,可以输入:
1 | x=100 |
显示变量的值,只需输入变量名,例如:
1 | x |
默认情况下,在变量没有赋值之前,bc假定所有变量的值为0。
一般情况下,bc计算时使用10作为基。但是,有时候您可能需要使用另一种基进行计算。bc允许对输入和输出指定不同的基。具体操作时,需要设置两个特殊的变量:ibase是用于输入的基;obase是用于输出的基。
例如,如果希望以基16显示答案,可以输入:
1 | obase=16 |
如果希望以基8输入数字,则需要使用:
1 | ibase=8 |
对于大于或等于10的基值,bc分别使用大写字母A、B、C、D、E、F表示值10、11、12、13、14和15.记住一定要使用大写字母,如果使用了小写字母,那么bc将会认为它是变量,从而使结果出错。
为方便起见,无论设置的输入基是什么,都可以使用这些大写字母。例如,即使现在使用的基是10,表达式A+1的值也是11。
和其他变量一样,直接输入ibase和obase自身就可以获得它们的当前值:
1 | ibase; obase |
但是,一定要小心。因为一旦设置了obase的值,所有的输出都将以这个基进行显示,显示的值可能会对您产生麻烦。例如,如果您输入:
1 | obase=16 |
那么您将看到:
1 | 10 |
这是因为此时所有的输出都以基16显示,而在基16中,值“16”就表示为10。
同理,一旦修改了ibase,在输入时也必须特别小心。例如,假设您设置了:
1 | ibase=16 |
现在希望将obase设置为基10,因此您输入:
1 | obase=10 |
但是,您忘了现在的输入基是16,而10在基16中其实是“16”。因此,obase还是被设置成基16。
为了避免出现这样的错误,可以使用字母A到F,无论ibase的值是多少,它们仍然是原来的值。因此,如果事情出现了混乱,您总可以这样重新设置基:
1 | obase=A; ibase=A |
下面准备讨论的命令是针对less分页程序的,因为大多数Unix系统使用它。如果man命令使用的是more或者pg,那么为了获得该特定分页程序的帮助摘要信息,您也只需按下h键。
| 通用命令 | |
|---|---|
| q | 退出 |
| h | 显示帮助信息 |
| 阅读说明书页 | |
| <Sapce> | 显示下一屏 |
| <PageDown> | 显示下一屏 |
| f | 显示下一屏 |
| <PageUp> | 显示上一屏 |
| b | 显示上一屏 |
| 搜索 | |
| /pattern | 向下搜索特定的模式 |
| ?pattern | 向上搜索特定的模式 |
| / | 向下搜索上一模式 |
| n | 向下搜索上一模式 |
| ? | 向上搜索上一模式 |
| N | 向上搜索上一模式 |
| 在说明书页中移动 | |
| <Return> | 向下移一行 |
| <Down> | 向下移一行 |
| <Up> | 向上移一行 |
| g(go to top) | 移到页的顶部 |
| G(go to bottom) | 移到页的底部 |
当阅读说明书页时,如果您键入一个!(感叹号),就可以在它之后键入一条shell命令。man程序将把这条命令发送给shell,而shell将运行这个命令。当命令结束后,可以按下<Return>键返回到man程序中。
当输入man命令时,Unix将显示整个手册页。但有时候,您可能只对一个简要描述感兴趣。在这种情况下,还有另外一种方法。
说明书页的Name节中包含一行描述。如果只想看这一行内容,可以键入man -f,后面跟一个或者多个命令的名称。例如:
1 | man -f time date |
在man命令的这种形式中,-f称为一个选项,代表单词“files”。每个说明书页都存储在一个单独的文件中。当使用-f选项时,就是告诉man查找哪些文件。
为了方便起见,可以使用命令whatis来取代man -f。例如,如果想显示时间,但是不能确定是使用time命令还是date命令,就可以输入下面两条命令中的任意一条:
1 | whatis time date |
您将看到类似下面的显示信息:
1 | time (7) - overview of time and timers |
第1、2、4行不是指向第1节的,可以忽略这三行。查看第3、5行,就可以知道您需要使用的命令是date。
众所周知,在输入man命令时,可以指定一个特定的节号(例如man 1 date)。至于man -f或者whatis命令,就不能再指定具体的节号。Unix总是搜索整个手册。因此,查找手册包含什么内容最好输入:
1 | whatis intro |
这样将会显示每个intro页的简要说明,例如:
1 | intro (1) - introduction to user commands |
当希望学习某条具体的命令时,可以使用man来显示该命令的说明书页。但是,如果您知道想做什么,但是却不能确定使用哪条命令,该怎么办呢?
解决方法就是使用带有-k选项的man命令。这样将搜索NAME节中包含特定关键字的命令(字母k代表“keyword”)。例如,假如您希望查找手册中与手册自身相关的所有条目,则可以输入:
1 | man -k manual |
为了方便起见,可以使用单个单词apropos待替man -k:
1 | apropos manual |
apropos命令搜索所有的单行命令描述,查找那些包含有指定字符串的描述。为了使该命令的功能更强大,在该命令中Unix不区分大小写字母。下面是上例的一些示例输出:
1 | aclocal-1.16 (1) - manual page for aclocal 1.16.1 |
Info系统是一个联机帮助系统,独立于Unix手册,用来记录GNU实用工具。因为许多类型的Unix——包括几乎所有的Linux系统,都使用GNU实用工具,所以大多数人发现了解如何同时使用联机手册和Info非常有用。
从表面上看,Info与联机手册有点相似。信息存储在文件中,每个文件一个主题,这与说明书页相似。这些文件称为Info文件,而且要阅读它们时,需要使用info程序。为此,只需键入info,后面跟着命令的名称即可。
1 | man date |
如果不能确定希望学习哪条命令,或者您希望浏览系统,则可以输入info命令本身:
1 | info |
当以这种方式启动Info时,它显示一个称为目录节点Directory Node的特殊节点。目录节点包含主要主题的列表,因此可以认为它是整个Info系统的主菜单。
在Info系统中有许多命令可以使用,下图总结了一些最重要的命令。
| 通用命令 | |
|---|---|
| q | 退出 |
| h | 启动帮助向导 |
| ? | 显示命令摘要列表 |
| 阅读节点 | |
| <PageDown> | 显示下一屏 |
| <Space> | 显示下一屏 |
| <Space> | (在节点底部时)跳转到下一个节点 |
| <PageUp> | 显示上一屏 |
| <Backspace> | 显示上一屏 |
| <Delete> | 显示上一屏 |
| <Backspace> | (在节点顶部时)跳转到上一个节点 |
| <Delete> | (在节点顶部时)跳转到上一个节点 |
| 在节点中移动 | |
| b | 跳转到当前节点的开头 |
| <Up> | 将光标向上移动一行 |
| <Down> | 将光标向下移动一行 |
| <Right> | 将光标向右移动一个位置 |
| <Left> | 将光标向左移动一个位置 |
| 在同一个文件中从一个节点跳转到另一个节点 | |
| n | 跳转到同一个文件的下一个节点 |
| p | 跳转到同一个文件的上一个节点 |
| t | 跳转到顶节点(Top Node,文件中的第一个节点) |
| 从一个文件跳转到另一个文件 | |
| <Tab> | 将光标移动到下一个链接上 |
| <Shift>-<Tab> | 将光标移动到上一个链接上 |
| <Return> | 到达链接指向的新节点或文件 |
| l | 跳转到上一个(刚才观看的)节点 |
| d | 跳转到目录节点(主菜单) |
为了显示默认变量,可以使用命令env:
1 | env |
在许多系统上,还有另外一个命令可以是用,这个命令是printenv:
1 | printenv |
名称printenv代表“print environment variables”。
使用不带选项或者参数的set命令可以显示所有的shell变量以及它们的值:
1 | set |
echo命令的任务就是显示赋予它的任何对象的值。为了显示一个变量的值,需要使用一个$(美元符号)字符。后面跟着用花括号括起来的变量名。例如,显示变量TERM的值,可以输入:
1 | echo ${TERM} |
如果没有歧义,也可以省略花括号:
1 | echo $TERM |
在shell中,一些标点符号字符称为“元字符”,它们拥有特殊的含义。为了防止shell解释元字符,需要将元字符包含在双引号中。这就告诉shell照字面意义接受字符。例如,为了显示尖括号中的TERM值。您可以输入下述命令:
1 | echo The terminal type is <$TERM>. |
但是,<和>字符是元字符,表示“重定向”,所以该命令不能正常运行。为此,您需要使用:
1 | echo "The terminal type is <$TERM>." |
所有的shell都允许使用echo命令显示文本和变量。至于Korn shell,还可以使用print命令:
1 | print "The terminal type is $TERM." |
对于Bourne shell家族,创建变量非常简单。所需做的全部事情就是键入一个名称,后跟一个=(等号)字符,再后跟一个值。变量的值必须是字符串。创建变量的语法为:
1 | NAME=value |
我们创建一个命名为HARLEY的变量,并将值cool赋给它:
1 | HARLEY="a cool boy" |
在Bourne shell家族中,每个新变量都自动地被设置成shell变量。使用export命令可以将变量导出到环境中。
因此,此时HARLEY只是一个shell变量。如果启动一个新shell或者运行一条命令,则新进程并不能访问HARLEY,因为它还不是环境变量。下面将HARLEY导出到环境中:
1 | export HARLEY |
现在HARLEY变量既是shell变量又是环境变量了。如果这时再启动一个新shell或者运行一条命令,那么它们就可以访问HARLEY。
export命令实际上允许同时设置变量并导出到环境中。该命令的语法为:
1 | export NAME[=value].. |
下面举一个简单的例子:
1 | export PAGER=less |
正如前面所述,当创建变量时,我们称这是在设置变量。当删除变量时,我们称这是在复位unset变量。变量极少需要复位,但是如果需要的话,则可以使用unset命令。该命令的语法比较简单:
1 | unset NAME.. |
下面举例说明:
1 | unset HARLEY WEEDLY |
在C-shell家族中,使用setenv和unsetenv命令可以设置(创建)或复位(删除)环境变量。设置或复位shell变量时,需要使用set和unset命令。
setenv命令的语法如下所示:
1 | setenv NAME |
注意,该命令中未使用=(等号)字符。
shell选项就像on/off开关一样。当打开一个选项时,就说设置了这个选项。这将告诉shell以某种方式运行。当关闭这个选项时,就说复位了这个选项。这也就是告诉shell停止以这种方式运行。
要设置一个选项,可以使用:
1 | set -o option |
要复位一个选项,可以使用:
1 | set +o option |
例如,假设shell正在运行,您希望设置monitor选项,则可以使用:
1 | set -o monitor |
为了复位monitor,可以使用:
1 | set +o monitor |
要显示shell选项的当前值,可以使用set -o或set +o命令本身:
1 | set -o |
一些指令在shell的内部,这意味着shell可以直接解释它们。这些指令是内部命令,通常称为内置命令builtin command。其他所有命令是外部命令。
一种查看某条命令是不是内置指令的快捷方式就是使用type命令。该命令的语法为:
1 | type command... |
例如:
1 | type date time set |
该命令的准确输出依赖于所使用的shell。例如,下面是在我系统上的输出:
1 | date is /usr/bin/date |
一些Unix/Linux系统对于内置命令拥有独立的说明书页。使用apropos命令可以查看系统是不是属于这种情况:
1 | apropos builtin |
Linux还有一个help命令,可以以若干种方式显示builtin说明书页的信息。该命令的语法为:
1 | help [-s] [command...] |
其中command是命令的名称。
开始时,可以通过输入help命令本身显示一个所有内置命令的摘要列表。
1 | help |
另外还可以使用help命令显示一条或多条具体命令的信息,例如:
1 | help pwd history kill help |
可以看出,help本事就是一条内置命令。
最后,如果只希望查看某条命令的语法,可以使用-s(syntax,语法)选项:
1 | help -s help |
绝大多数情况下应该用expliccit关键字修饰构造函数,我们往往不期望构造函数被用于隐式类型转换
将二元操作符函数如operator==和operator*的两个参数命名为lhs和rhs,分别意为left-hand-side和right-hand-side
将指向一个T型对象的指针命名为pt,意为pointer to T,例如
1 | Widget* pw; // pw = "ptr to Widget" |
对references类似,rw可能是个reference to Widget,ra则是个reference to Airplane
这个条款提供的视角很有意思,C++威力巨大,但涉及的东西太多太杂,融合了太多东西。将C++视为一个由相关次语言sublanguage组成的联邦而非单一语言或许对认识C++有所帮助
主要的四个次语言:C, Object-Oriented C++,Template C++, STL。当从一个次语言切换到另一个次语言时,所遵从的高效编程策略也许会随之改变。例如对内置(C-like)类型而言pass by value通常比pass by reference更高效,但当从C part of C++移往Object-Oriented C++时,对于由用户定义的类型,pass by reference to const往往比pass by value更高效
C++高效编程守则视状况而变化,取绝于你使用C++的哪一部分
1 |
|
书上一个例子很有意思,假如一个类需要一个成员常量,我们最好将其声明为static类型变量,声明之后还得记得在类外定义它,例如
1 | class CostEstimate |
但又有一个很有趣的问题,如果刚在类里声明了一个静态变量(例如static const int num;),紧接着下一行就用这个值指定数组元素个数int arr[num];,此时num还未定义,没有值,所以编译没法通过。于是我们曲线救国,将原本的静态变量换为enum { num = 5; }即可解决问题
对于单纯变量,最好以const对象或enums替换#define
对于形似函数的宏,最好改用inline函数替换#define
将某些东西声明为const可帮助编译器侦测出错误用法。const可被施加于任何作用域的对象、函数参数、函数返回类型、成员函数本体
编译器强制实施bitwise constness,但你编写程序时应该使用“概念上的常量性”conceptual constness
当const和non-const成员函数有着实质等价的实现时,令non-const版本调用const版本可避免代码重复
为内置型对象进行手工初始化,因为C++不保证初始化它们
构造函数最好使用成员初值列member initialization list,而不要在构造函数本题内使用赋值操作assignment。初值列列出的成员变量,其排序次序应该和它们在class中的声明次序相同
为免除“跨编译单元之初始化次序”问题,请以local static对象替换non-local static对象
编译器可以暗自为class创建default构造函数、copy构造函数、copy assignment操作符,以及析构函数
你自己实现了其中的某函数后,编译器就不会实现默认版的它了。而且即使你没有实现copy assignment操作符,特定情况下编译器会拒绝替你默认实现,例如成员变量是const,或是reference,又或者这个类的父类将它的copy assignment设为private等情况
为驳回编译器自动(暗自)提供的机能,可将相应的成员函数声明为private并且不予实现。使用像Uncopyable这样的base class也是一种做法
1 | class Uncopyable { |
polymorphic base classes应该声明一个virtual析构函数。如果class带有任何virtual函数,它就应该拥有一个virtual析构函数
Classes的设计目的如果不是作为base classes使用,或不是为了具备多态性,就不该声明virtual析构函数
给一个类添加一个纯虚函数让它成为一个abstract class,这样它就不能被实例化了,有时这正是我们想要的,但此时我们手上没有任何pure virtual函数,怎么办?那就把析构函数声明成纯虚函数就好
1 | class AWOV { //AWOV = "Abstract w/o Virtuals" |
这个class有一个pure virtual函数,所以它是一个抽象class,又由于它有个virtual析构函数,所以你不需要担心析构函数的问题。然而,你必须为这个pure virtual析构函数提供一份定义:
1 | AWOV::~AWOV() {} //pure virtual析构函数的定义 |
析构函数是自外而内的,也就是最深层派生most derived的那个class其析构函数最先被调用,然后像是剥洋葱一样,一层层向上调用其父类的析构函数,最终将会调用这个抽象类的析构函数。因此,如果不给出该抽象类析构函数的定义,连接器会发出抱怨
析构函数绝对不要吐出异常。如果一个被析构函数调用的函数可能抛出异常,析构函数应该捕捉任何异常,然后吞下它们(不传播)或结束程序
如果客户需要对某个操作函数运行期间抛出的异常做出反应,那么class应该提供一个普通函数(而非在析构函数中)执行该操作
在构造和析构期间不要调用virtual函数,因为这类调用从不下降至derived class(比起当前执行构造函数和析构函数的那层)
令赋值操作符返回一个reference to *this
1 | class Bitmap { ... }; |
原先我认为上述版本的运算符重载函数考虑已足够周全,但书中指出其存在异常安全性问题:先将this->pb指向的空间释放掉,如果下一行申请空间时出错(例如,空间不足)怎么办呢?
几种方法可以弥补
1 | Widget& Widget::operator=(const Widget& rhs) |
确保当对象自我赋值时operator=有良好行为,其中技术包括比较“来源对象”和“目标对象”的地址、精心周到的语句顺序、以及copy-and-swap
确定任何函数如果操作一个以上的对象,而其中多个对象是同一个对象时,其行为仍然正确
Copying函数应该确保复制“对象内的所有成员变量”及“所有base class成分”
简单说,当新增/删除一个成员变量时,应考虑对构造/析构/拷贝构造/拷贝复制函数进行相应修改
在子类的拷贝构造和拷贝赋值函数中,除了将子类的各成员变量进行拷贝外,还应调用父类的拷贝构造/拷贝赋值。每个类都这么写的话,无论多少层继承都能递归地拷贝下去
1 | class Date { ... }; |
不要尝试以某个copying函数实现另一个copying函数。应该将共同机能放进第三个函数中,并由两个copying函数共同调用
1 | void f() |
一个函数动态申请了一块内存,在使用后将内存释放。上述代码初看起来很妥当,但若干情况下f()可能无法删除它得自createInvestment()的资源对象——或许是因为“…“区域过早的return语句,或许是在该区域抛出的异常或者别的,甚至即使现在不存在问题, 也许将来代码维护人员在对该函数未能充分理解的情况下做了些改动,导致风险的出现,等等。总之,上面这种做法是有风险的
解决方法是,用对象来管理资源
1 | void f() |
这样,无论何时退出函数,auto_ptr的析构函数都将忠实地回收资源。以上代码中createInvestment()返回的资源被当做其管理者auto_ptr的初值。实际上“以对象管理资源”的观念常被称为“资源取得时机便是初始化时机”Resource Acquisition Is Initialization, RAII。因为我们几乎总是在获得一笔资源后于同一语句内以它初始化某个管理对象,而管理对象运用析构函数确保资源被释放
为防止资源泄漏,请使用RAII对象,它们在构造函数中获得资源并在析构函数中释放资源
两个常被使用的RAII classes分别是tr1::shared_ptr和auto_ptr。前者通常是较佳选择,因为其copy行为比较直观。若选择auto_ptr,复制动作会使它(被复制物)指向null
复制RAII对象必须一并复制它所管理的资源,所以资源的copying行为决定RAII对象的copying行为
普遍而常见的RAII class copying行为是:抑制copying、实行引用计数法reference counting。不过其他行为也都可能被实现
APIs往往要求访问原始数据raw resource,所以每一个RAII class应该提供一个“取得其所管理之资源”的办法
对原始资源的访问可能是经由显示转换或隐式转换,一般而言显示转换比较安全,但隐式转换对客户比较方便
如果你在new表达式中使用了[],必须在相应的delete表达式中也使用[]。如果你在new表达式中不使用[],一定不要在相应的delete表达式中使用[]
以独立语句将newed对象存储于(置于)智能指针内。如果不这样做,一旦异常被抛出,有可能导致难以察觉的资源泄漏
好的接口很容易被正确使用,不容易被误用。你应该在你的所有接口中努力达成这些性质
“促进正确使用”的办法包括接口的一致性,以及与内置类型的行为兼容
“阻止误用”的办法包括建立新类型、限制类型上的操作,束缚对象值,以及消除客户的资源管理责任
tr1::shared_ptr支持定制型删除器custom deleter。这可防范DLL问题,可被用来自动解除互斥锁等等
几乎每一个class都要求你面对以下提问,而你的回答往往导致你的设计规范:
新type的对象应该如何被创建和销毁?
对象的初始化和对象的赋值该有什么样的差别?
新type的对象如果被passed by value,意味着什么?记住,copy构造函数用来定义一个type的pass-by-value该如何实现
什么是新type的“合法值”?
你的新type需要配合某个继承图系inheritance graph吗?
你的新type需要什么样的转换?
什么样的操作符和函数对此新type而言是合理的?
什么样的标准函数应该被驳回?那些正是你必须声明为private者
谁该取用新type的成员?
什么是新type的“未声明接口”undeclared interface?
你的新type有多么一般化?
你真的需要一个新type吗?
尽量以pass-by-reference-to-const替换pass-by-value。前者通常比较高效,并可避免切割问题slicing problem
以上规则并不适用于内置类型,以及STL的迭代器和函数对象。对它们而言,pass-by-value往往比较适当
绝不要返回pointer或reference指向一个local stack对象,或返回reference指向一个heap-allocated对象,或返回pointer或reference指向一个local static对象而有可能同时需要多个这样的对象
切记将成员变量声明为private。这可赋予客户访问数据的一致性、可细微划分访问控制、允诺约束条件获得保证,并提供class作者以充分的实现弹性
protected并不比public更具封装性(当public成员变量发生改变时,多少客户代码需要相应做出改动?当protected成员变量发生改变时,多少derived class代码需要做出改动?)
宁可拿non-member non-friend函数替换member函数。这样做可以增加封装性、包裹弹性packaging flexibility和机能扩充性
书上举的例子是说,如果你的class需要一个便利函数,这个函数的唯一作用就是调用另外几个成员函数,我们既可以将该函数写为一个成员函数,也可以写为普通函数。而写成普通函数更好,因为若把其写成成员函数,它就拥有访问private变量的权力,哪怕它并没有用这权力做什么,而写成普通函数可直接让其丧失该权力,提供封装性。封装并不是一味指把数据和操作数据的函数捆绑在一起,封装的目的是隐藏、降低耦合
如果你需要为某个函数的所有参数(包括被this指针所指的那个隐喻参数)进行类型转换,那么这个函数必须是个non-member
当std::swap对你的类型效率不高时,提供一个swap成员函数,并确保这个函数不抛出异常
如果你提供一个member swap,也应该提供一个non-member swap用来调用前者,对于classes(而非templates),也请特化std::swap
调用swap时应针对std::swap使用using声明式,然后调用swap并且不带任何“命名空间资格修饰”
为“用户定义类型”进行std templates全特化是好的,但千万不要尝试在std内加入某些对std而言全新的东西
尽可能延后变量定义式的出现。这样做可增加程序的清晰度并改善程序效率
如果可以,尽量避免转型,特别是在注重效率的代码中避免dynamic_casts,如果有个设计需要转型动作,试着发展无需转型的替代设计
如果转型是必要的,试着将它隐藏于某个函数背后。客户随后可以调用该函数,而不需要将转型放进他们自己的代码内
宁可使用C++-style(新式)转型,不要使用旧式转型。前者很容易辨识出来,而且也比较有着分门别类的职掌
避免返回handles(包括references、指针、迭代器)指向对象内部。遵守这个条款可增加封装性,帮助const成员变量的行为像个const,并将发生“虚吊号码牌”dangling handles的可能性降至最低
异常安全函数Exception-safe functions即使发生异常也不会泄漏资源或允许任何数据结构败坏。这样的函数区分为三种可能的保证:基本型、强烈型、不抛异常型
“强烈保证”往往能够以copy-and-swap实现出来,但“强烈保证”并非对所有函数都可实现或具备现实意义
函数提供的“异常安全保证”通常最高只等于其所调用之各个函数的“异常安全保证”中的最弱者
将大多数inlining限制在小型、被频繁调用的函数身上。这可使日后的调试过程和二进制升级binary upgradability更容易,也可使潜在的代码膨胀问题最小化,使程序的速度提升机会最大化
不要只因为function templates出现在头文件,就将它们声明为inline
支持“编译依存最小化”的一般构想是:相依于声明式,不要相依于定义式。基于此构想的两个手段是Handle classes和Interface classes
程序库头文件应该“完全且仅有声明式”full and declaration-only forms的形式存在。这种做法不论是否涉及template都适用
“public继承”意味is-a。适用于base classes身上的每一件事情一定也适用于derived classes身上,因为每一个derived class对象也都是一个base class对象
derived classes内的名称会掩盖base classes内的名称。在public继承下从来没有人希望如此
为了让被遮掩的名称再见天日,可使用using声明式或转交函数forwarding functions
接口继承和实现继承不同。在public继承之下,derived classes总是继承base class的接口
pure virtual函数只具体指定接口继承
简朴的(非纯)impure virtual函数具有指定接口继承及缺省实现继承
non-virtual函数具体指定接口继承以及强制性实现继承
virtual函数的替换方案包括Non-Virtual Interface, NVI手法及Strategy设计模式的多种形式。NVI手法自身是一个特殊形式的Template Method设计模式
将机能从成员函数移到class外部函数,带来的一个缺点是,非成员函数无法访问class的non-public成员
tr1::function对象的行为就像一般函数指针。这样的对象可接纳“与给定之目标签名式target signature兼容”的所有可调用物callable entities
绝对不要重新定义一个继承而来的缺省参数值,因为缺省参数值都是静态绑定,而virtual函数——你唯一应该覆写的东西——却是动态绑定
1 | class Base |
1 | Base* pb1 = new Base(); |
函数是动态绑定,参数是静态绑定!!!
复合composition的意义和public继承完全不同
在应用域application domain,复合意味着has-a(有一个)。在实现域implementation domain,复合意味is-implemented-in-terms-of`(根据某物实现出)
private继承意味is-implemented-in-terms of(根据某物实现出)。它通常比复合composition的级别低。但是当derived class需要访问protected base class的成员,或需要重新定义继承而来的virtual函数时,这么设计是合理的
和复合不同,private继承可以造成empty base最优化。这对致力于“对象尺寸最小化”的程序开发者而言,可能很重要
多重继承比单一继承复杂。它可能导致新的歧义性,以及对virtual继承的需要
virtual继承会增加大小、速度、初始化(及赋值)复杂度等等成本。如果virtual base classes不带任何数据,将是最具有实用价值的情况
多重继承的确有正当用途。其中一个情节涉及“public继承某个Interface class”和“private继承某个协助实现的class”的两相组合
classes和templates都支持接口interfaces和多态polymorphism
对classes而言接口是显式的explicit,以函数签名为中心。多态则是通过virtual函数发生于运行期
对template参数而言,接口是隐式的implicit,奠基于有效表达式。多态则是通过template具现化和函数重载解析function overloading resolution发生于编译器
声明template参数时,前缀关键字class和typename可互换
请使用关键字typename标识嵌套从属类型名称,但不得在base class lists(基类列)或member initialization list(成员函数列)内以它作为base classes修饰符
1 | template<typename T> |
可在derived class templates内通过”this->”指涉base class templates内的成员名称,或藉由一个明白写出的“base class资格修饰符“完成
Template生成多个classes和多个函数,所以任何template代码都不该与某个造成膨胀的template参数产生相依关系
因非类型模板参数non-type template parameters而造成的代码膨胀,往往可消除,做法是以函数参数或class成员变量替换template参数
因类型参数type parameters而造成的代码膨胀,往往可降低,做法是让带有完全相同二进制表述binary representations的具现类型instantiation types共享实现码
请使用member function templates(成员函数模板)生成“可接受所有兼容类型”的函数
如果你声明member templates用于“泛化copy构造”或“泛化assignment操作”,你还是需要声明正常的copy构造函数和copy assignment操作符
1 | template<class T> |
当我们编写一个class template,而它提供之“与此template相关的”函数支持“所有参数之隐式转换”时,请将那些函数定义为“class template内部的friend函数”
Traits classes使得“类型相关信息”在编译期可用。它们以templates和“templates特化”完成实现
整合重载技术overloading后,traits classes有可能在编译期对类型执行if…else测试
Template metaprogramming(TMP, 模板元编程)可将工作由运行期移往至编译器期,因而得以实现早期错误侦测和更高的执行效率
TMP可被用来生成“基于政策选择组合”based on combinations of policy choices的客户定制代码,也可用来避免生成对某些特殊类型并不适合的代码
set_new_handler允许客户指定一个函数,在内存分配无法获得满足时被调用
Nothrow new是一个颇为局限的工具,因为它只适用于内存分配;后继的构造函数还是可能抛出异常
有许多理由需要写个自定的new和delete,包括改善效能、对heap运用错误进行调试、收集heap使用信息
operator new应该内含一个无穷循环,并在其中尝试分配内存,如果它无法满足内存需求,就该调用new-handler。它也应该有能力处理0 bytes申请。Class专属版本还应该处理“比正确大小更大的(错误)申请”
operator delete应该在收到null指针时不做任何事。Class专属版本则还应该处理“比正确大小更大的(错误)申请”
当你写了一个placement operator new,请确定也写出了对应的placement operator delete。如果没有这样做,你的程序可能会发生隐微而时断时续的 内存泄漏
当你声明placement new和placement delete,请确定不要无意识(非故意)地遮掩了它们的正确版本
所谓placement new和placement delete,就是相较于正常的operator new/operator delete有更多参数的版本
常规版operator new如
1 | void* operator new(std::size_t size) throw(std::bad_alloc) {} |
而定制版placement new如
1 | void* operator new(std::size_t size, std::ostream& logStream) throw(std::bad_alloc) {} |
写了一个placement new就一定要写一个对应(参数相同)的placement delete
1 | void operator delete(std::size_t size, std::ostream& logStream) throw() {} |
可以这样使用placement new(假设以上函数均为class Widget的成员函数)
1 | Widget* pw = new (std::cerr) Widget(); |
我们的new多了一个ostream类型的参数,由此知该语句所调用的operator new版本是定制版的。我们知道,new操作符实际分为两个步骤:调用operator new申请内存以及调用构造函数初始化对象。如果第一步申请内存就出了问题(如内存空间不足)则会调用new_handler()函数进行处理;而如果内存申请成功,但调用构造函数出现异常,由于对象并没有真正的构造出来,pw尚未被赋值,客户手上也就没有指针指向该被归还的内存。取消步骤一并恢复旧观的责任因此落到了C++运行期系统身上。运行期系统则会调用与operator new相对应的operator delete来释放内存。所谓相对应,就是指参数个数、参数类型均相同operator delete
注意:就算你的placement operator new没有对应的placement operator delete,编译器也不会报错
严肃对待编译器发出的警告信息。努力在你的编译器的最高(最严苛)警告级别下争取“无任何警告”的荣誉
不要过度倚赖编译器的报警能力,因为不同的编译器对待事情的态度并不相同。一旦移植到另一个编译器上,你原本倚赖的警告信息有可能消失
作者零五年写的这书,C++98之后的新标准直到11年才出来,tr1应该就是C++11之前对该标准的称呼
TR1添加了智能指针(例如tr1::shared_ptr)、一般化函数指针tr1::function、hash-based容器、正则表达式以及另外10个组件的支持
TR1自身只是一份规范。为获得TR1提供的好处,你需要一份实物。一个好的实物来源是Boost
Boost是一个社群,也是一个网站。致力于免费、源码开放、同僚复审的C++程序库开发。Boost在C++标准化过程中扮演深具影响力的角色
Boost提供许多TR1组件实现品,以及其他许多程序库
现在是2021/12/29,下月9号考计网,自我感觉良好,昨天把官网所有习题全做了,没遇到很大困难。写这么一小段是提醒以后看我这篇博客复习计网的朋友,《计算机网络:自顶向下》这本书官网自带很好的实验与各章节习题,无论是深入学习网络原理还是考前刷题巩固基础都是极好的,这本书是真的很良心,可是老师授课时却全然没有提及过官网配套学习资源的事情。。。
这些东西错过真的血亏啊!!!贴一个官网在这里,打算复习知识点、巩固基础的朋友千万别错过这么好的资源,官网的题是必做的。毕竟书都是人家写的,无条件相信就好。
主机host就是端系统end system
端系统通过通信链路communication link和分组交换机packet switch连接到一起
分组交换机包括:路由器router和链路层交换机link-layer switch
端系统通过因特网服务提供商Internet Service Provider, ISP接入因特网
多数分组交换机在链路的输入端使用存储转法传输store-and-forward transmission机制。存储转发传输是指在交换机能够开始向输出链路传输该分组的第一个比特之前,必须接收到完整的分组
通过网络链路和交换机移动数据有两种基本方法:电路交换circuit switching和分组交换packet switching,在电路交换中,预留了端系统间沿路径通信所需的资源(缓存,链路传输速率)。传统的电话网络就是电路交换的例子,在电话拨通前,已在电话网上留出资源,保证了能以恒定速率传输数据。而分组交换并不预留资源,因此当其他分组也需要经过该链路传输时,可能发生拥塞,则该分组不得不在传输链路发送测的缓存中等待而产生时延。
链路上的电路是通过频分复用Frequency-Division Multiplexing, FDM或时分复用Time-Division Multiplexing, TDM实现的。电路交换的缺点是不能实现资源的高效利用。比如以时分复用为例,假设将一秒分为1帧,而1帧分为5个时隙,则一个时隙为0.2秒。若建立了一个连接需要通过该链路传数据,该连接分得一个时隙,那么即使该链路上此时就这一个连接在传数据,在1秒内它也只能使用分配给它的0.2秒传数据,剩下0.8秒浪费掉了
一个分组从一个节点传播到后继节点,该分组在每个节点经受了几种不同类型的实现,其中最为重要的是处理时延processing delay,排队时延queuing delay,传输时延transmission delay和传播时延propagation delay,这几个时延加起来就是节点的总时延nodal processing delay
5层因特网协议(自顶向下):应用层,运输层,网络层,链路层,物理层
7层ISO OSI参考模型(自顶向下):应用层,表示层,会话层,运输层,网络层,链路层,物理层
两个协议模型相比较,OSI模型多了两层:表示层(使得通信的应用程序能够解释交换数据的含义)和会话层(提供了数据交换的定界和同步功能,包括了建立检查点和恢复方案的方法)。因特网缺少了OSI参考模型中的两个层次,我们问:这些层次提供的服务不重要吗?如果一个应用程序需要这些服务之一将会怎样呢?因特网对这两个问题的回答相同:这留给应用程序开发者处理。如果一个服务重要,应用程序开发者就应该在应用程序中构建该功能
典型应用层协议如:HTTP(提供Web文档的请求和传送)、SMTP(提供了电子邮件报文的传输)和FTP(提供两个端系统之间的文件传送);典型的运算层协议如TCP和UDP;典型的网络层协议如IP;链路层的例子如以太网,WiFi和电缆接入网的DOCSIS协议
位于应用层的信息分组称为报文message,运输层的分组称为报文段segment,网络层负责将数据报datagram从一台主机传到另一台主机,我们称链路层分组为帧frame。对于运输层报文段、网络层数据报和链路层帧而言,一个分组具有两种类型的字段:首部字段和有效载荷字段payload field
链路层交换机实现了物理层和链路层,路由器实现了物理层、链路层和网络层,这意味着路由器能实现IP协议,而链路层交换机不能
拒绝服务攻击Denial-of-Service (DoS) attack短时间内猛烈地向目标发送流量,拥塞网络,使服务陷入瘫痪;分布式DoSDistributed Dos, DDoS从多个源点向目标发送流量
记录每个流经的分组的副本的被动接收机被称为分组嗅探器packet sniffer;将具有虚假源地址的分组注入因特网的能力被称为IP哄骗IP spoofing
由于套接字是建立网络应用程序的可编程接口,因此套接字也称为应用程序与网络之间的应用程序编程接口Application Programming Interface, API
Web的应用层协议是超文本传输协议HyperText Transfer Protocol, HTTP
服务器向客户发送被请求的文件,而不存储任何关于该客户的状态信息。假如某个特定的客户在短短几秒内两次请求同一对象,服务器并不会因为刚刚为该客户提供了该对象就不再做出反应,而是重新发送该对象,就像服务器已经完全忘记不久之前所做过的事一样。因为HTTP服务器并不保存关于客户的任何信息,所以我们说HTTP是一个无状态协议stateless protocol
往返时间Round-Trip Time, RTT:是指一个短分组从客户到服务器然后再返回客户所花费的时间
典型的HTTP请求报文
1 | GET /somedir/page.html HTTP/1.1 //请求行 request line |
请求行有三个字段:方法字段、URL字段和HTTP版本字段;首部行Host: www.someschool.edu指明了对象所在的主机;Connection: close指明不使用持续连接,让服务器发送完请求的对象后就关闭这条连接;User agent用来指明用户代理,即向服务器发送请求的浏览器类型;最后,Accept-language表示用户希望得到该对象的法语版本
Web缓存器Web cache也叫代理服务器proxy server,是能够代表初始Web服务器来满足自己的磁盘存储的网络实体。可以配置用户的浏览器,使得用户的所有HTTP请求首先指向Web缓存器。一旦服务器被配置,每个对某个对象的服务器请求首先被定向到该Web缓存器。举例而言,假设浏览器正在请求对象http://www.someschool.edu/campus.gif,将会发生如下情况:
1)浏览器创建一个到Web缓存器的TCP连接,并向Web缓存器中的对象发送一个HTTP请求
2)Web缓存器进行检查,看看本地是否存储了该对象副本。如果有,Web缓存器向客户浏览器用HTTP响应报文返回该对象
3)如果没有,它就打开一个与该对象的初始服务器(即www.someschool.com)的TCP连接。Web缓存器则在这个缓存器到服务器的TCP连接上发送一个对该对象的HTTP请求。在收到该请求后,初始服务器向该Web缓存器发送具有该对象的HTTP响应
4)当Web缓存器接收到该对象时,它在本地存储空间存储一份副本,并向客户的浏览器用HTTP响应报文发送该副本(通过现有的客户浏览器和Web缓存器之间的TCP连接)
因特网电子邮件系统的三个主要组成部分:用户代理user agent、邮件服务器mail server和简单邮件传输协议Simple Mail Transfer Protocol, SMTP;一个典型的邮件发送过程是:从发送方的用户代理开始,传输到发送方的邮件服务器,再传输到接收方的邮件服务器,然后在这里被分发到接收方的邮箱中
SMTP是因特网电子邮件中主要的应用层协议。它使用TCP可靠数据传输服务,从发送方的邮件服务器向接收方的邮件服务器发送邮件。每台邮件服务器上既运行SMTP客户端又运行SMTP服务器端
为描述SMTP的基本操作,我们观察一种常见的情景。假设Alice想给Bob发送一封简单的ASCII报文。
1)Alice调用她的邮件代理程序并提供Bob的邮件地址,撰写报文,然后指示用户代理发送该报文
2)Alice的用户代理把报文发送给她的邮件服务器,在那里该报文被放在报文队列中
3)运行在Alice的邮件服务器上的SMTP客户端发现了报文队列中的这个报文,它就创建一个到运行Bob的邮件服务器上的SMTP服务器的TCP连接
4)在经过一些初始SMTP握手后,SMTP客户通过该TCP连接发送Alice的报文
5)在Bob的邮箱服务器上,SMTP的服务器端接收该报文。Bob的邮件服务器然后将该报文放入Bob的邮箱中
6)在Bob方便的时候,他调用用户代理阅读该报文
思考:Alice想要向Bob发送电子邮件,她首先将邮件推送到自己的邮件服务器,再由邮件服务器将邮件发给Bob的邮件服务器。为什么该过程要分成两步呢?主要是因为如果不通过Alice的邮件服务器进行中继,Alice的用户代理将没有任何办法到达一个不可达的目的地接收服务器。通过首先将邮件存放在自己的邮件服务器中,Alice的邮件服务器可以重复地尝试向Bob的邮件服务器发送该报文。
还有一个值得思考的点:像Bob这样的接收方,是如何通过运行其本地PC上的用户代理获得位于他的某ISP的邮件服务器上的邮件呢?要知道,用户代理不能使用SMTP得到报文,因为取报文是一个拉操作,而SMTP是一个推协议。通过引入一个特殊的邮件访问协议来解决这个难题,该协议将Bob邮件服务器上的报文传送给他的本地PC。目前流行的一些邮件访问协议:第三版的邮局协议Post Office Protocol Version 3, POP3、因特网邮件访问协议Internet Mail Access Protocol, IMAP以及HTTP
主机能有许多不同的名字。人类喜欢便于记忆的主机名标识方式,而路由器喜欢定长的、有层次结构的IP地址。为了折中这种偏好,需要一种能进行主机名到IP地址转换的目录服务。这就是域名系统Domain Name System, DNS的主要任务。DNS是一个由分层的DNS服务器DNS server实现的分布式数据库,也是一个使得主机能够查询分布式数据库的应用层协议。DNS协议运行在UDP之上,使用53号端口。
考虑运行在某用户主机上的浏览器请求URLwww.someschool.com/index.html页面时会发生什么现象。为了使用户的主机能够将一个HTTP请求报文发送到Web服务器www.someschool.com,该用户主机必须获得www.someschool.com的IP地址。其做法如下。
1)同一台用户主机上运行着DNS应用的客户端
2)浏览器从上述URL中抽出主机名www.someschool.com,并将这台主机名传给DNS应用的客户端
3)DNS客户向DNS服务器发送一个包含主机名的请求
4)DNS客户最终会收到一份回答报文,其中含有对应该主机的IP地址
5)一旦浏览器接收到来自DNS的该IP地址,它能够向位于该IP地址80端口的HTTP服务器发起一个TCP连接
除了进行主机名到IP地址的转换外,DNS还提供一些重要的服务:主机别名host aliasing,有复杂主机名的主机能拥有一个或多个(也许)更容易记忆的别名,但只有一个规范主机名canonical hostname;邮件服务器别名mail server aliasing,各项功能基本同主机别名;负载分配load distribution
运输层协议为运行在不同主机上的应用进程之间提供了逻辑通信logic communication功能。从应用程序角度看,通过逻辑通信,运行不同进程的主机好想直接相连一样
网络层提供了主机之间的逻辑通信,而运输层为运行在不同主机上的进程之间提供了逻辑通信
IP是不可靠服务unreliable service
将主机间交付扩展到进程间交付被称为运输层的多路复用transport-layer multiplexing与多路分解demultiplexing
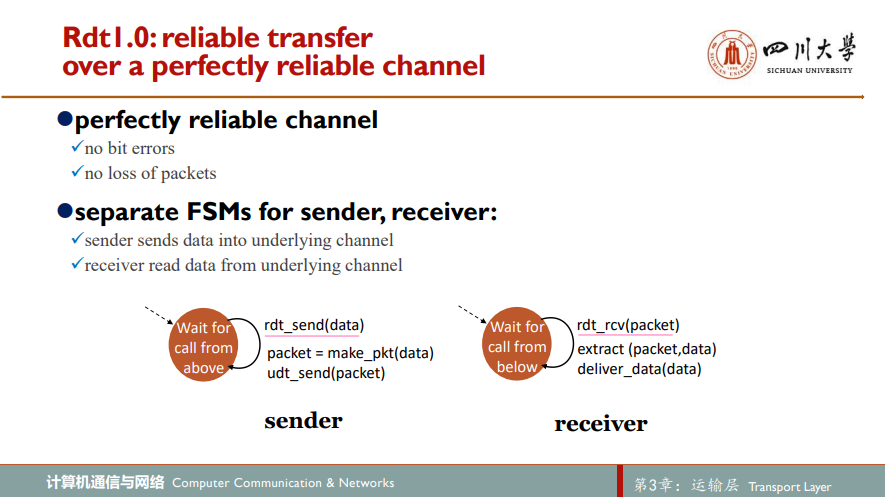
1.经完全可靠信道的可靠数据传输:rdt1.0
假定分组按发送次序进行交付
没有差错!没有丢包!
2.经具有比特差错信道的可靠数据传输:rdt2.0
仍然假设按序交付
没有丢包!可能出错
每发送一个分组,发送方等待接收方反馈,若收到NAK,重传分组
每接收一个分组,接收方发送反馈(ACK,NAK)
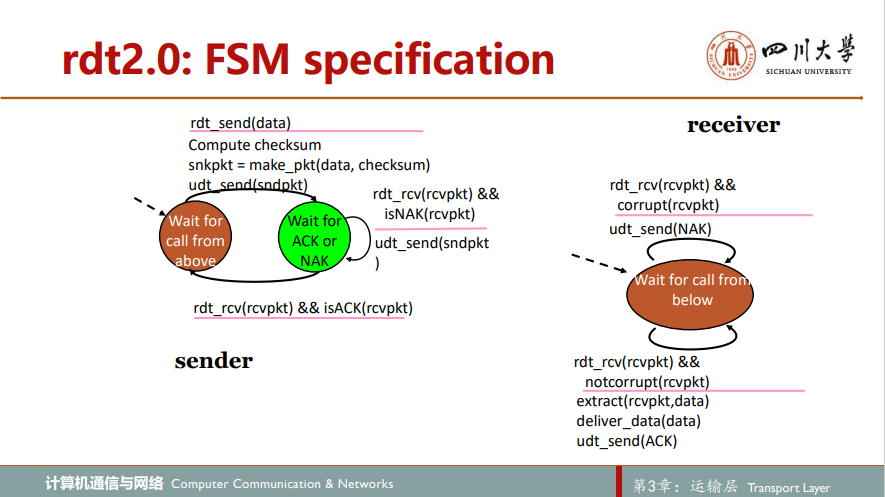
注意到:当发送方处于等待ACK或NAK状态时,它不能从上层获得更多数据;这就是说,rdt_send()事件不可能出现;仅当接收到ACK并离开该状态时才能发生这样的事件。因此,发送方将不会发送一块新数据,除非发送方确信接收方已正确接收当前分组。由于这种行为,rdt2.0这样的协议被称为停等stop-and-wait协议
3.进一步考虑比特差错的可靠数据传输:rdt2.1
rdt2.0只考虑到了对发送方发往接收方的数据进行差错检测,但却忽略了接收方的反馈出错这种情况。假设发送方向接收方发送了一个分组,无论出错与否,接收方都向其发送反馈分组,不幸的是该反馈分组在传输过程中产生比特差错,当发送方接收到该信号后发现该分组是错误的,这时它该怎么办呢?rdt2.0协议无法解决这个问题,于是我们对其稍作改良:当发送方发现反馈分组是错误的时,它不知晓接收方到底有没有正确接收分组,为保险起见,发送方重发刚才的分组。但这里又有个问题:接收方如何区分其接收到的分组是一个新的分组还是重传分组呢?为实现能够对分组进行区分,在数据分组中添加一个新字段,将发送方分组的序号sequence number放在该字段,于是接收方只需要检查序号即可确定收到的分组是否是一次重传
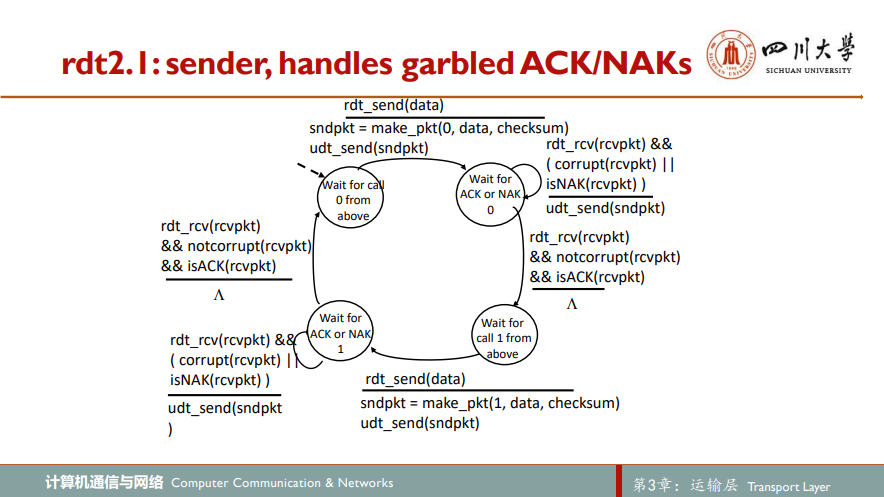
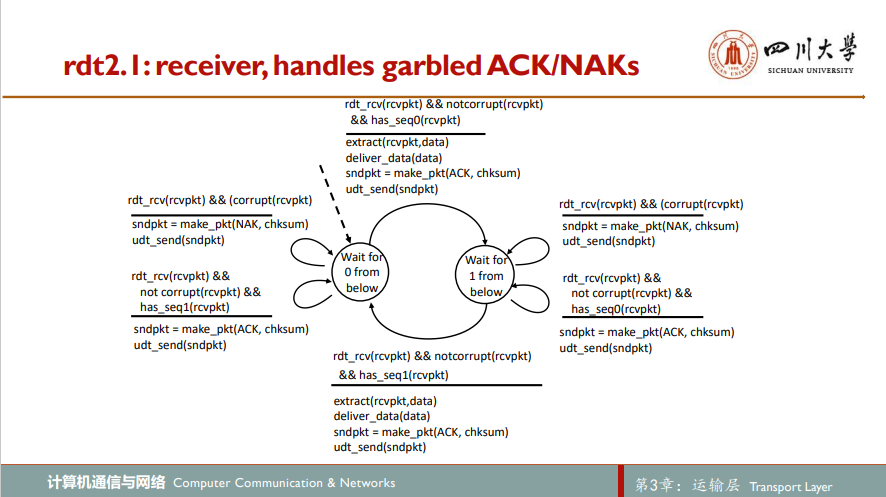
4.rdt2.1的变种:rdt2.2
rdt2.2实现的功能和rdt2.1完全相同,只是实现的方法不同。rdt2.2取消了NAK信号,无论接收方接收到的是预期想要的分组还是一个出错的分组都使用ACK信号进行反馈。如果接收方在期待一个序号值为0的分组,而接收到的分组序号值为1,接收方知道这是一个重传分组,于是向发送方发送一个ACK 1信号,代表接收方已接收到该序列号为1的重传分组。当发送方接收到此ACK 1信号时,自然知道该发送新的、序列值为0的分组
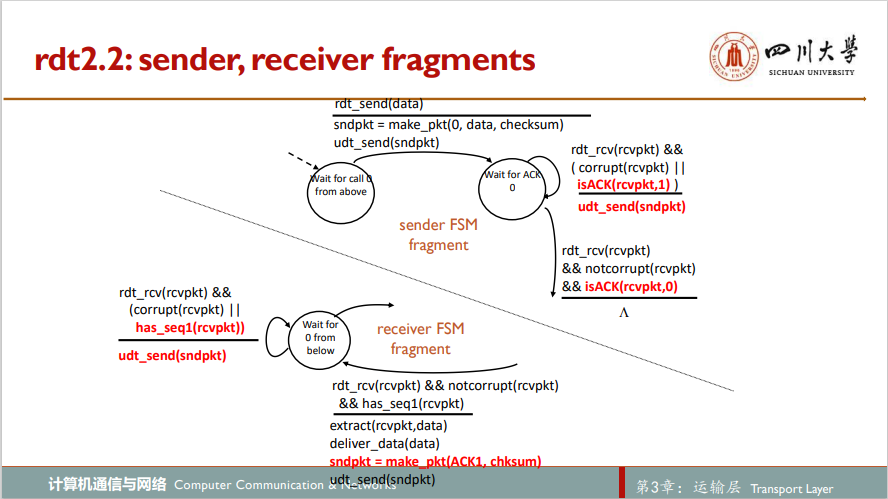
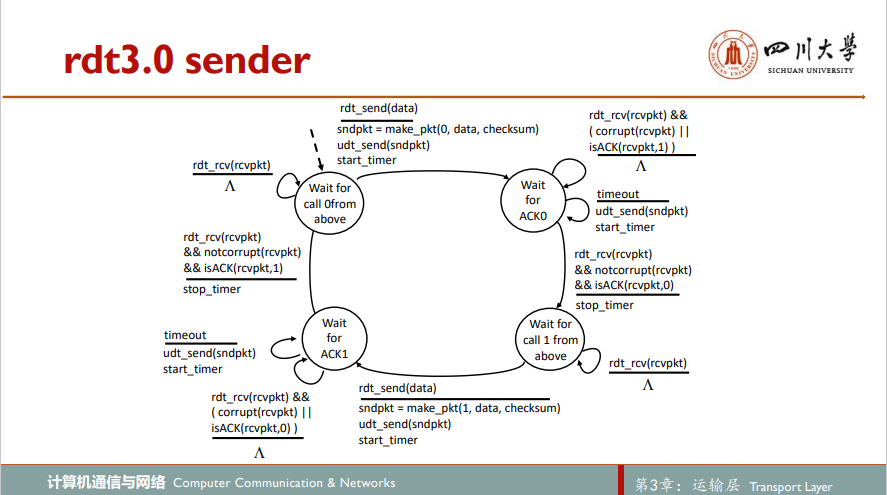
5.经具有比特差错的丢包信道的可靠数据传输:rdt3.0
现假定除比特受损外,底层信道还会丢包。协议必须处理两个问题:怎样检查丢包以及发生丢包后该做些什么。发送方发送分组后,等待一段时间,若没能得到应答(可能发送分组丢失,或是反馈分组丢失,亦或是网络拥塞,分组堵在路上了),为保险起见,发送方重传分组,再等待一段时间,如此往复直至收到接收方应答反馈
为实现基于时间的重传机制,需要一个倒计时计数器countdown timer,在一个给定的时间量过期后,可中断发送方。因此,发送方需要能够做到:1.每次发送一个分组(包括第一次分组和重传分组)时,启动一个定时器;2.响应定时器中断(采取适当的动作);3.终断定时器。于是便得到rdt3.0协议
rdt3.0的接收方相较于rdt2.2的接收方FSM并没有变化
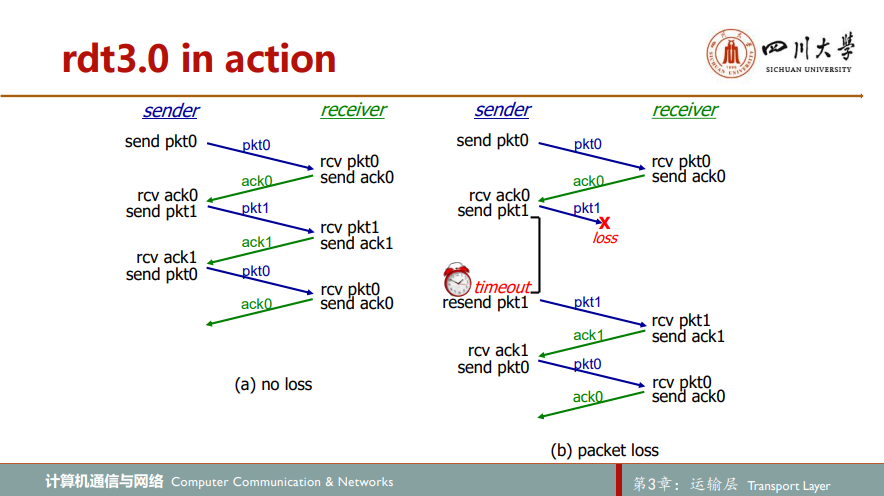
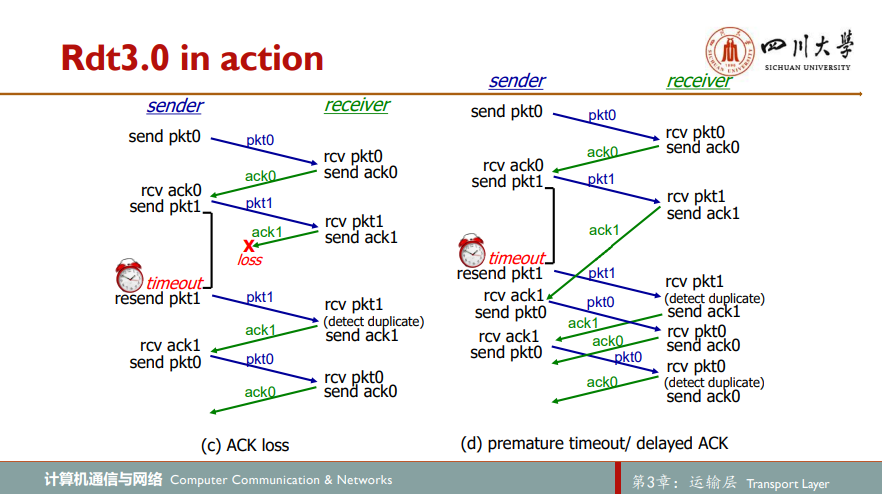
rdt3.0给人感觉不错,已经是一个考虑比较周全的协议,但其实质仍是一个停等协议,效率太低,故考虑流水线pipelining技术,一次性传多个分组,带来的影响有:1)必须增加序号范围,因为每个输送中的分组(不计算重传的)必须有一个唯一的序号,而且也许有多个在输送中的未确认报文;2)协议发送方和接收方不得不缓存多个分组;3)如何处理丢失、损坏及延时过大的分组
解决流水线差错恢复两种基本方法是:回退N步Go-Back-N, GBN和选择重传Selective Repeat, SR
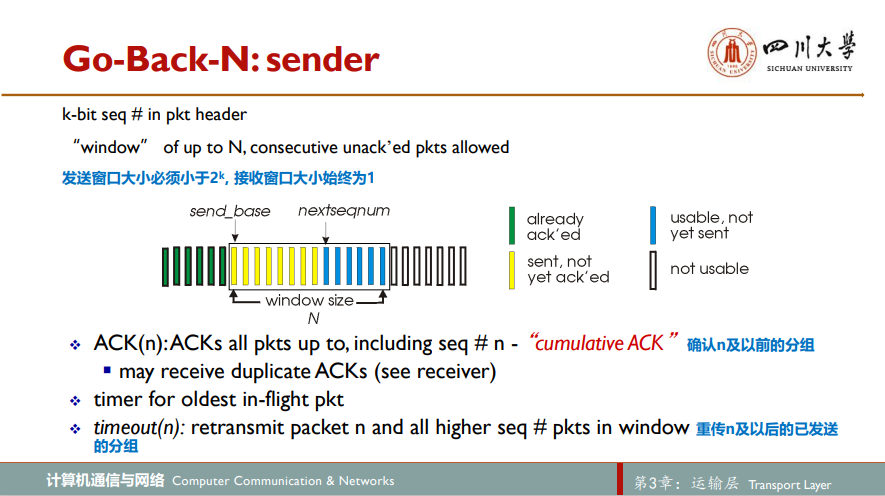
图中显示了发送方看到的GBN协议的序号范围,如果我们将基序号base定义为最早未确认分组的序号,将下一个序号nextseqnum定义为最小的未使用序号(即下一个待发分组的序号),则可将序号范围分割为4段。在[0, base - 1]段内的序号对应于已经发送并被确认的分组,[base, nextseqnum - 1]段内的序号对应于已经发送并被确认的分组。[nextseqnum, base + N - 1]段内的序号能用于那些要被立即发送的分组(如果有数据来自上层的话),最后,大于或等于base + N的序号是不能使用的,直到当前流水线中未被确认的分组(特别是序号为base的分组)已得到确认为止
已被发送但还未确认的分组的许可序号范围可以被看成是一个在序号范围内长度为N的窗口。随着协议的运行,该窗口在序号空间向前滑动。因此,N常被称为窗口长度window size,GBN协议也常被称为窗口滑动协议sliding-window protocol
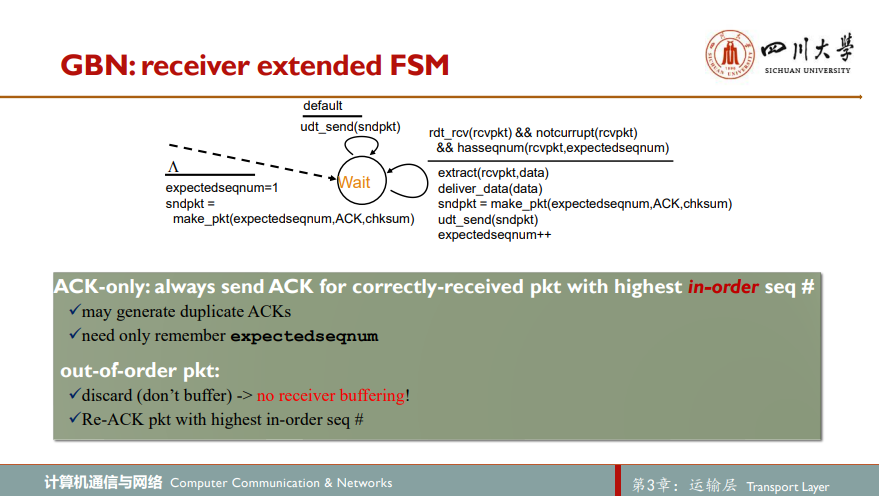
注意,在GBN协议中,接收端窗口大小始终为1,当其接收到正确但失序的分组只是将其简单的丢弃
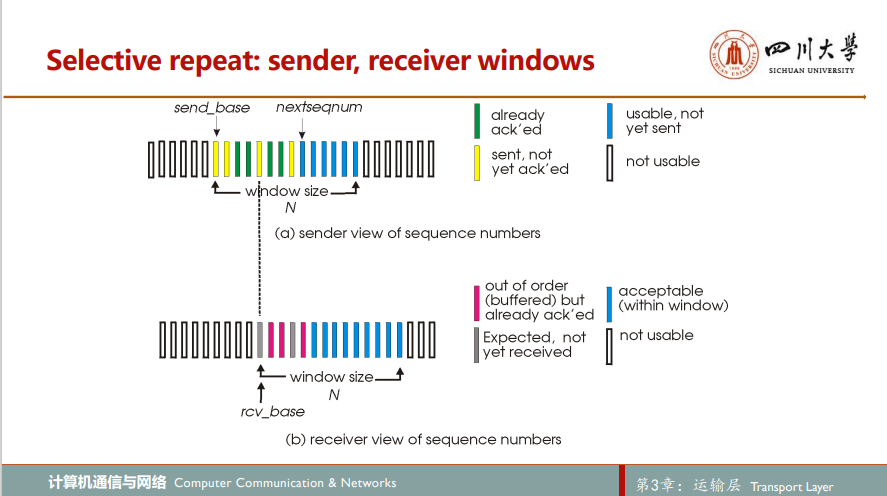
我个人更喜欢选择重传
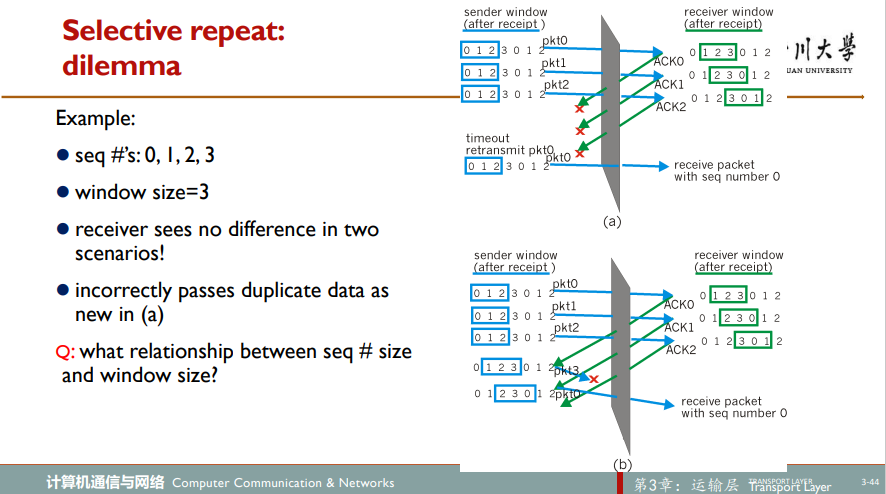
不过需注意,接收端窗口大小需小于等于发送端窗口大小的一半(向下取整),否则会出问题。试想,如果发送端窗口大小为2X,接收端窗口大小为X。发送端先发送序号1 ~ X共X个分组,接收端全接收到,刚好把接收端窗口填满,接收端向后移动X个单位,假设接收端的所有ACK信号全部丢失,待超时时,发送端重发1 ~ X分组,接收端窗口此时期待的序号范围为X + 1 ~ 2X,保证发送端重发的分组的序号不会和接收端窗口期代的新的序号有重叠,避免了上图里情况的发生
TCP被称为是面向连接的connection-oriented,这是因为在一个应用程序可以开始向另一个应用程序发送数据之前,这两个进程必须先“握手”。这种TCP“连接”不是一条像在电路交换网络中的端到端TDM或FDM电路。相反,该“连接”是一条逻辑连接,其共同状态仅保留在两个通信端系统的TCP程序中。由于TCP协议只在端系统中运行,而不在中间的网络元素(路由器和链路层交换机)中运行,所以中间的网络元素不会维持TCP连接状态。事实上,中间路由器对TCP连接完全视而不见,它们看到的是数据报,而不是连接
一旦建立起一条TCP连接,两个应用进程之间就可以互相发送数据了。客户进程通过套接字传递数据流,TCP将这些数据引导到该连接的发送缓存send buffer。TCP可从缓存中取出并放入报文段中的数据数量受限于最大报文段长度Maximum Segment Size, MSS。MSS通常根据最初确定的由本地发送主机发送的最大链路层帧长度(即所谓的最大传输单元Maximum Transmission Unit, MTU)来设置。注意到MSS是指报文段里应用层数据的最大长度,而不是指包含首部的TCP报文段的最大长度
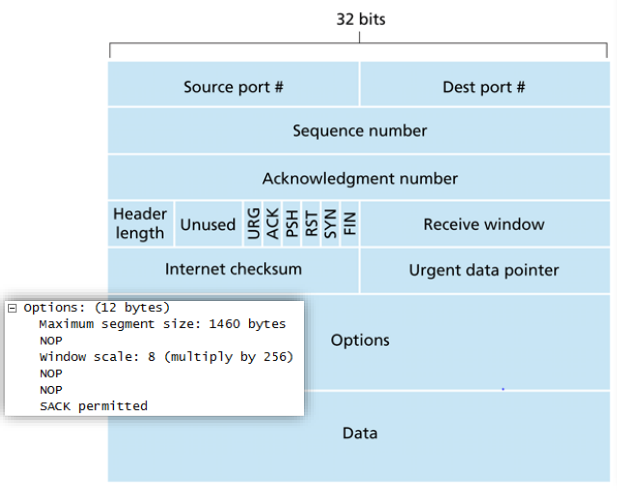
TCP把数据看成一个无结构的、有序的字节流。一个报文段的序号sequence number for a segment因此是该报文段首字节的字节流编号。主机A填充进报文段的确认号是主机A希望从主机B收到的下一字节的序号。例如,假设主机A已收到来自主机B的编号为0~535的所有字节,同时假设它打算发送一个报文段给主机B。主机A等待主机B的数据流中字节536及之后的所有字节。所以主机A就会在它发往主机B的报文段的确认号字段中填上536
TCP采用累计确认cumulative acknowledgment
TCP为它的应用程序提供了流量控制服务flow-control service以消除发送方使接收方缓存溢出的可能性。流量控制因此是一个速度匹配服务,即发送方的发送速率与接收方应用程序的读取速率相匹配。TCP发送方也可能因为IP网络的拥塞而被遏制;这种形式的发送方控制被称为拥塞控制congestion control。流量控制和拥塞控制采取的动作非常相似,但它们是针对完全不同的原因而采取的措施。流量控制是为了更好的服务两个端系统上的应用程序,而拥塞控制则是着眼整个网络
TCP通过让发送方维护一个称为接收窗口receive window的变量来提供流量控制。该窗口用于给发送方一个指示——该接收方还有多少可用的缓存空间。假设主机A通过一条TCP连接向主机B发送要给大文件,主机B为该连接分配了一个接收缓存,并用RevBuffer表示其大小。我们定义以下变量:
LastByteRead:主机B上的应用程序从缓存读出的数据流的最后一个字节的编号
LastByteRcvd:从网络中到达的并且已经放入主机B接收缓存中的数据流的最后一个字节的编号
由于TCP不允许已分配的缓存溢出,因此LastByteRcvd - LastByteRead <= RevBuffer成立
接收窗口用rwnd表示,根据缓存可用空间的数量来设置。rwnd = RcvBuffer - [LastByteRcvd - LastByteRead],由于该空间是随着时间变化的,所以rwnd是动态变化的
开始时,主机A设定rwnd = RcvBuffer,主机A轮流跟着两个变量,LastByteSent和LastByteAcked,注意到这两个变量之差就是主机A发送到连接但未被确认的数据量。通过将未确认的数据量控制在值rwnd以内,就可以保证主机A不会使主机B的接收缓存溢出。因此有LastByteSent - LastByteAcked <= rwnd
TCP连接建立:三次握手three-way handshake
1)客户端的TCP首先向服务器端的TCP发送一个特殊TCP报文段。该报文段不包含应用层数据,但报文段首部的一个标志位SYN被置1,并且客户会随机选择一个初始化序号client_isn
2)一旦包含TCP SYN报文段的IP数据报到达服务器主机,服务器从数据报中提取出TCP SYN报文段,为该TCP连接分配TCP缓存和变量,并向客户发送允许连接的报文段。该报文段同样不含应用层数据,SYN位置一,确认号字段被置为client_isn + 1,同时将服务器的初始序号server_isn放置到报文段的序号字段中。该允许连接报文段被称为SYNACK报文段SYNACK segment
3)客户端收到SYNACK报文段后,也要为该TCP连接分配缓存和变量,并再向服务器端发送报文来对服务器的允许连接的报文段进行确认(通过将server_isn + 1放置到TCP报文段首部的确认字段来完成此项工作)。因为连接已建立,所以该报文SYN位置零,并且可以在此报文段携带客户到服务器的数据
一旦完成以上三个步骤,客户和服务器主机就可以互相发送包括数据的报文段了。在以后的每一个报文段中,SYN位都置零
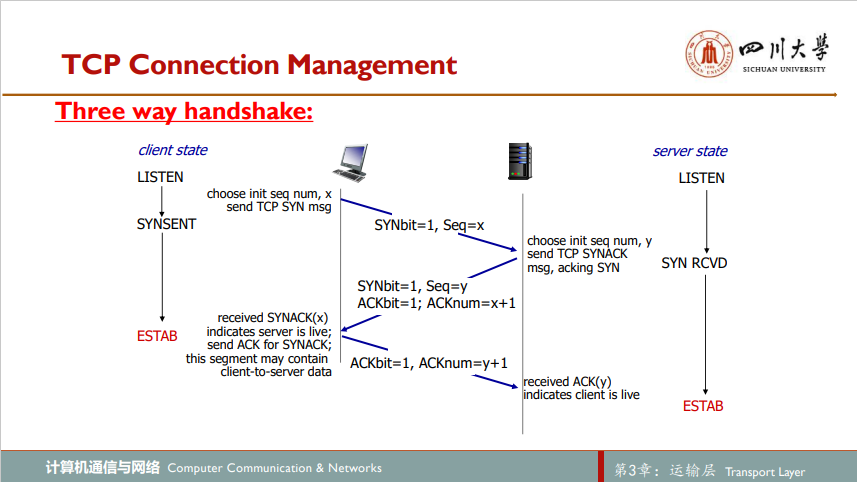
第一次握手SYN = 1,客户初始序号,没有数据但消耗一个序号;第二次握手SYN = 1,服务器初始化序号,没有数据,也消耗一个序号;第三次握手SYN = 0,SYN置零,可以包含数据
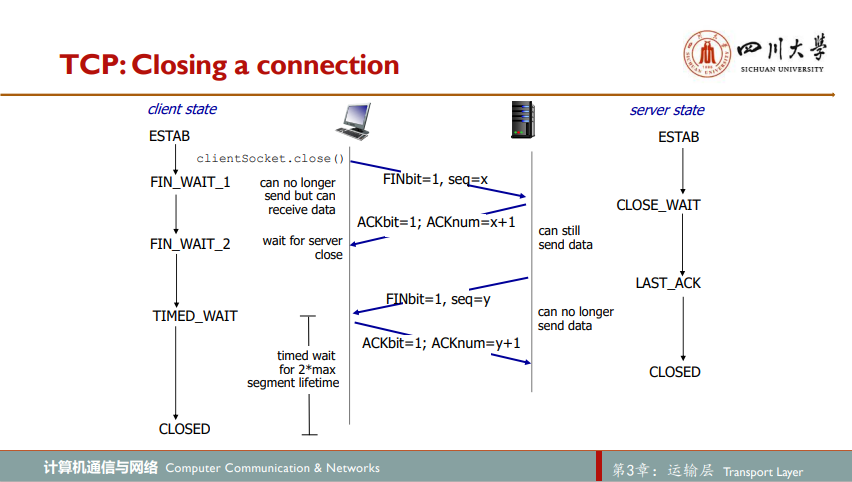
TCP连接关闭:四次挥手
参与一条TCP连接的两个进程中的任意一个都能终止该连接。当连接结束后,主机中的资源(即缓存和变量及端口)都将被释放
1)打算关闭连接的一方A向另一方B发送一个特殊的TCP报文段。该报文段首部的一个标志位FIN被置一
2)当B接收到该FIN报文段后,就向发送方A回送一个ACK确认报文段
3)B也向A发送一个FIN置一的TCP报文段
4)当A收到该报文段后,A同理回送一个ACK确认报文段
至此,双方互相确认完毕断开连接,回收资源
实际中,当第四步A回送确认报文段后并不离开回收资源,而会等一会(可能三十秒或一分钟?具体时间与具体实现相关),A处于TIME_WAIT状态。假定ACK丢失,TIME_WAIT状态使A重传最后的确认报文。经等待后,连接就正式关闭,释放资源
SYN洪泛攻击SYN flood attack
我们在三次握手中已看到,服务器为了响应一个收到的SYN,分配初始化连接变量和缓存,然后服务器发送一个SYNACK进行响应,并等待来自客户的ACK报文段。如果某客户不发送ACK来完成三次握手的第三步,最终(可能半分钟后)服务器终止并断开该半开连接并回收资源,这为DoS攻击即SYN洪泛攻击提供了环境。随着这种SYN报文纷沓而来,服务器不断为这些半开连接分配资源,导致最终资源消耗殆尽。一种称为SYN cookie的技术能有效防御该种攻击
SYN cookie工作原理:当服务器收到一个SYN报文段时并不分配资源。服务器生成一个初始TCP序列号,该序列号是SYN报文段的源和目的IP地址与端口以及仅有该服务器知道的秘密数的一个复杂函数(散列函数)。这种精心制作的初始序列号被称为cookie。服务器则发送具有这种特殊初始序列号的SYNACK分组。重要的是,服务器并不记忆该cookie或任何对应于SYN的其他状态信息
如果客户是合法的,它将返回一个ACK报文,该报文的确认字段中的数值应该等于用该报文的源和目的IP地址与端口算出来的cookie值再加一。服务器为满足该条件的客户分配资源,建立连接。如此这般,无论客户不返回ACK报文或是返回一个伪造的报文,都不会消耗服务器资源
TCP采用端到端拥塞控制而不是网络辅助的拥塞控制,因为IP层不向端系统提供显式的网络拥塞反馈。如果一个TCP发送方感知沿该路径有拥塞,则发送方会降低其连接发送流量的速率。但这种方法提出了三个问题:1)一个TCP发送方如何限制它向其他连接发送流量的数据呢?2)一个TCP发送方如何感知从它到目的地之间的路径存在拥塞呢?3)采用何种算法来改变其发送速率呢?
运行在发送方的TCP拥塞控制机制跟踪一个额外的变量,即拥塞窗口congestion window。拥塞窗口表示为cwnd,它对一个TCP发送方能向网络中发送流量的速率进行了限制。已发送但没被确认的数据量满足以下限制:
LastByteSent - LastByteAcked <= min{ cwnd, rwnd }
为关注拥塞控制(与流量控制形成对比),假设rwnd足够大,以至于可以忽略接收窗口的限制;因此在发送方中未被确认的数据量受限于cwnd。通过调整cwnd大小即可动态控制发送速率
简单!丢包事件发生(超时或3次冗余ACK)即意味着网络拥塞,发送方应减小拥塞窗口大小,降低传输速率;另一方面,若发送方收到对于以前未确认的报文段的确认,则将其理解为一切正常的指示,增大拥塞窗口大小,增加发送速率。而且,如果确认以低速率到达,则拥塞窗口应以低速率增大;确认以高速率达到则拥塞窗口以高速率增大
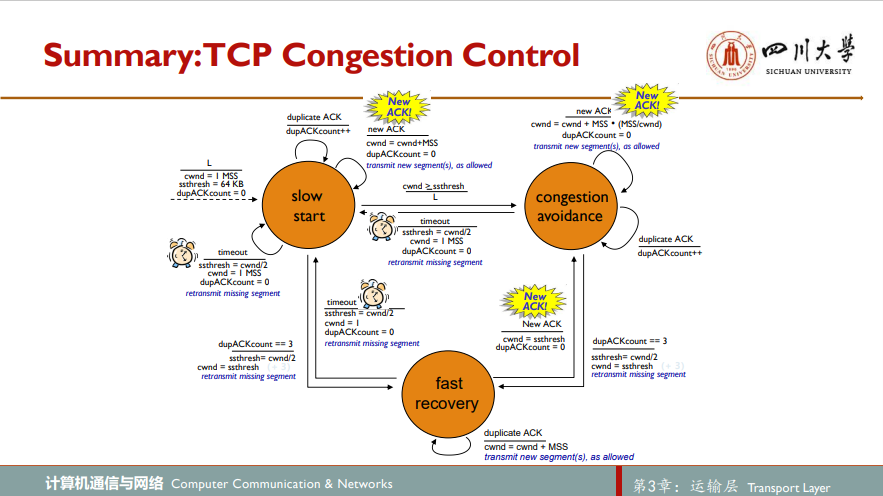
通过广受赞誉的TCP拥塞控制算法TCP congestion control algorithm实现。该算法包括三个主要部分:慢启动、拥塞避免和快速恢复(快速恢复是推荐部分,而不是必需的)
slow start当一条TCP连接开始时,cwnd的值通常初始置为一个MSS的较小值,每当传输报文段首次被确认就就增加一个MSS。这样,1至2,2至4,4至8…每过一个RTT,发送速率就翻番,直至丢包事件发生(超时或三次冗余ACK)

若超时,将状态变量ssthresh(”慢启动阈值“的速记)的值设为此时cwnd大小的一半,重设cwnd值为1并重新进行慢启动。当cwnd窗口大小又逐渐增大至ssthresh,继续使cwnd翻番可能有些鲁莽,于是进入拥塞避免阶段
在拥塞避免阶段,TCP无法每个RTT再将cwnd值翻番,而是采取保守方法,每次RTT只将其增大一个MSS大小
懒得打字了
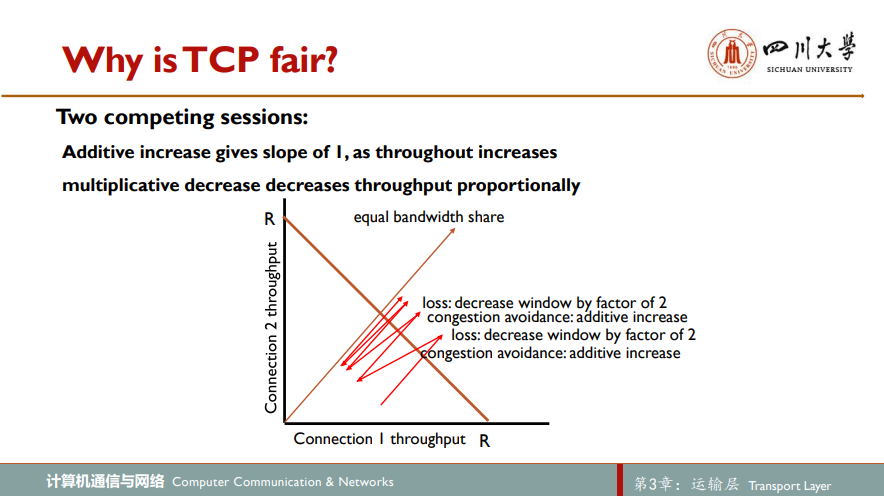
考虑K条TCP链接,每条都有不同的端到端路径,但都经过一段传输速率为R bps的瓶颈链路。假设每条连接都在传输一个大文件,而且无UDP流量通过该段瓶颈链路。如果每条连接的平均传输速率接近R/K,即每条连接都得到相同份额的链路带宽,则认为该拥塞控制机制是公平的。而TCP的AIMD拥塞控制算法是公平的
转发forwarding是指将分组从一个输入链路接口转移到适当的输出链路接口的路由器本地动作。转发发生的时间尺度很短(通常为几纳秒),因此通常用硬件来实现
路由选择routing是指确定分组从源到目的地所采用的端到端路径的网络范围处理过程。时间尺度长的多(通常几秒),因此通常软件实现
考虑一个驾驶员从宾夕法尼亚州到佛罗里达州的行程。在行程中该驾驶员经过了许多立交桥。我们能够认为转发就像通过单个立交桥的过程:一辆汽车从其道路上进入立交桥的一个入口,并且决定应当走哪条路来离开该立交桥。我们可以把路由选择看作是规划从宾夕法尼亚州到佛罗里达州行程的过程:在着手行程前,驾驶员已经查阅了地图并在许多可能的路径中选择一条,其中每条路径都由一系列经立交桥连接的路段组成
网络层的数据平面执行主要功能就是转发,而网络层的控制平面执行的主要功能是路由选择
每台网络路由器中有一个关键元素是它的转发表forwarding table。路由器检查到达分组首部的一个或多个字段,进而使用这些首部值在其转发表中索引来转发分组
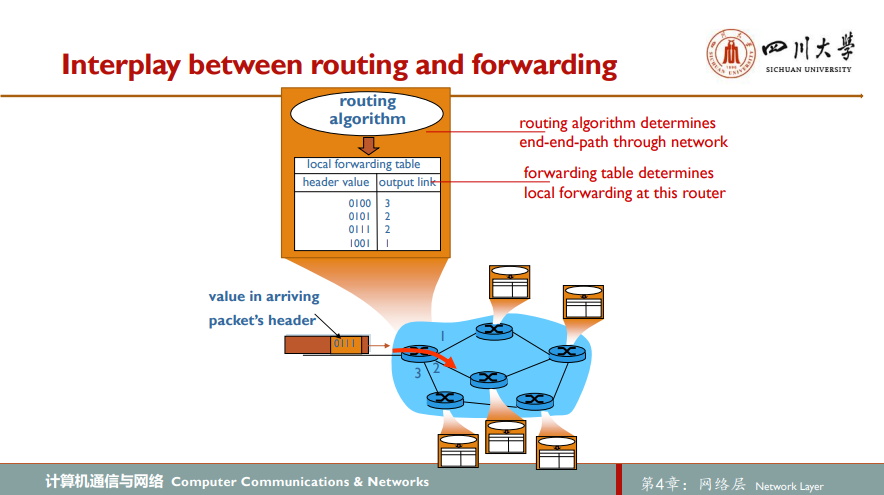
于是我们不禁思考:路由器中的转发表一开始是如何配置的呢?
传统的方法是,在每条路由器中运行路由选择算法,由路由选择算法决定插入该路由器转发表中的内容,故每台路由器都包含转发和路由选择两种功能。一台路由器中的路由选择算法与在其他路由器中的路由选择算法通信,以计算出它的转发表值。这种通信又是如何执行呢?通过根据路由选择协议交换包含路由选择信息的路由选择报文!
而另一种方法,软件定义网络Software-Defined Networking, SDN,将路由选择从路由器中分离:远程控制器计算和分发转发表以供每台路由器使用,而路由设备仅执行转发。远程控制器可能实现在具有高可靠性和冗余的远程数据中心中,并可能由ISP或某些第三方管理。路由器和远程控制器是如何通信呢?通过交换包含转发表和其他路由选择信息的报文
下图显示了一个通用路由器体系结构的总体视图
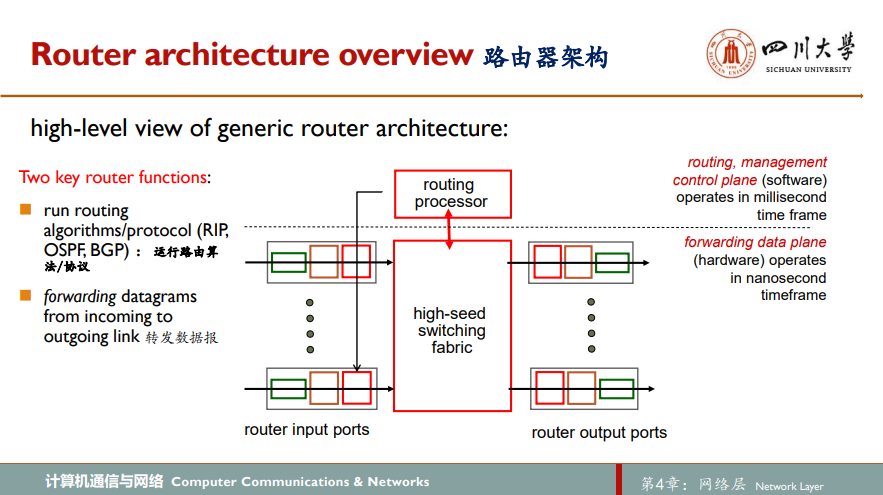
图左边的输入端口input port表现为一个大的矩形,每个端口矩形内部还有三个方框,其中左起第一个绿色方框负责执行终结入物理链路的物理层功能(线路端接),中间棕色方块代表端口负责与位于入链路远端的数据链路层交互来执行数据链路层功能(数据链路处理(协议,拆封)),右边的红色方块代表端口要执行的查找功能(查找,转发,排队)
存在三种交换结构用于总体视图中交换结构的实现:经内存交换,经总线交换和经互联网交换
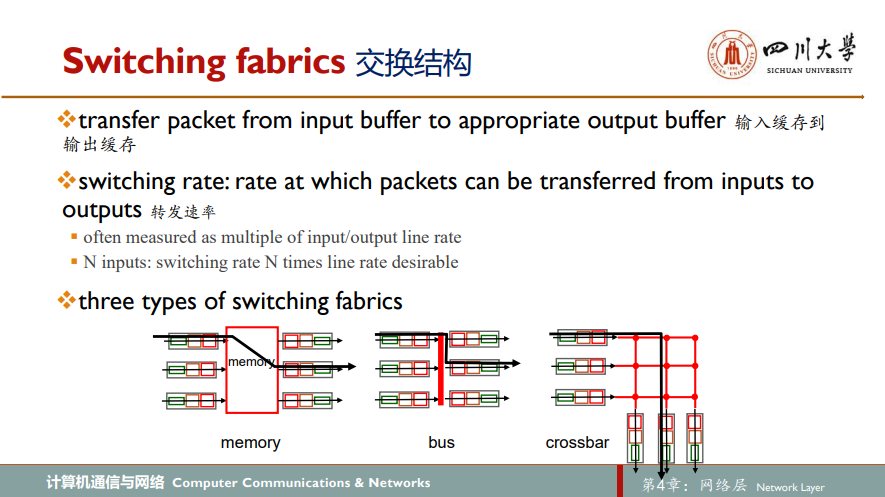
通过将输入端口传入的分组数据复制于内存,由路由选择处理器于其首部提取目的地址,在转发表中找出适当的输出端口,并将该分组复制到输出端口的缓存中。假设内存带宽为每秒可读写进内存或从内存读出最多B个分组,则总转发吞吐量必然小于B/2。也要注意到不能同时转发两个分组,即使它们有不同的目的端口,因为经过共享系统总线一次仅能执行一个内存读写
输入端口经一根共享总线将分组直接传输到输出端口,不需要路由选择处理器的干预。通过让输入端口为分组预先计划一个交换机内部标签(首部),指示本地输出端口,使分组在总线上传送和传输到输出端口。该分组能由所有输出端口收到,但只有与该标签匹配的端口才能保存该分组,然后标签在输出端口被去除。采用该方法,除了一个分组外所有其他分组必须等待,因为一次只有一个分组能够跨越总线
如上述PPT中右侧图片所示,纵横式交换机是非阻塞的non-blocking,即只要没有其他分组当前被转发到该输出端口,转发到输出端口的分组将不好被到达输出端口的分组阻塞。当然,如果两个不同的输入端口同时打算转发至相同输出端口,则其中一个需要等待
输出端口做的事情有点像是输入端口的逆过程,从左到右三个子方框分别代表:1)排队(缓存管理),2)数据链路处理(协议,封装),3)线路端接
何时会出现输入排队呢?试想,一台路由器有N个输入端口,假设每个时间单位内每个输入端口均收到一个分组,若在该时间单位内交换结构不能将N个分组全部转发,那么必然部分输入端口在该时间单位内没能来得及将分组转发,而一个时间单位后又有新的分组到达。如果这种情形一致持续,每个时间单位内都有部分输入端口得不到转发,总体来看,平均每个输入端口的队列将越来越长,直至最终缓存溢出,丢包事件发生
何时会出现输出排队呢?假设交换结构是纵横式的,一个时间单位内N个输入端口均收到分组,且这些分组全都需要转发至同一输出端口,而交换结构工作得够快,能够在一个时间单位内将N个分组全部转发至目标端口。而不幸的是该输出端口没有能力在一个时间单位内将N个分组全部传输,如果在一段时间内持续不断的许多分组转发至同一输出端口,当输出端口没有足够的内存来缓存一个入分组时,就必须做出决定:要么丢弃到达的分组(采用一种称为弃尾drop-tail的策略),要么删除一个或多个已排队的分组来为新来的分组腾出空间。在某些情况下,在缓存填满之前便丢弃一个分组,以向发送方提供一个拥塞信号是有利的。这种策略统称为主动队列管理Active Queue Management, AQM,随机早期检测Random Early Detection, RED算法是得到最广泛研究和实现的AQM算法之一
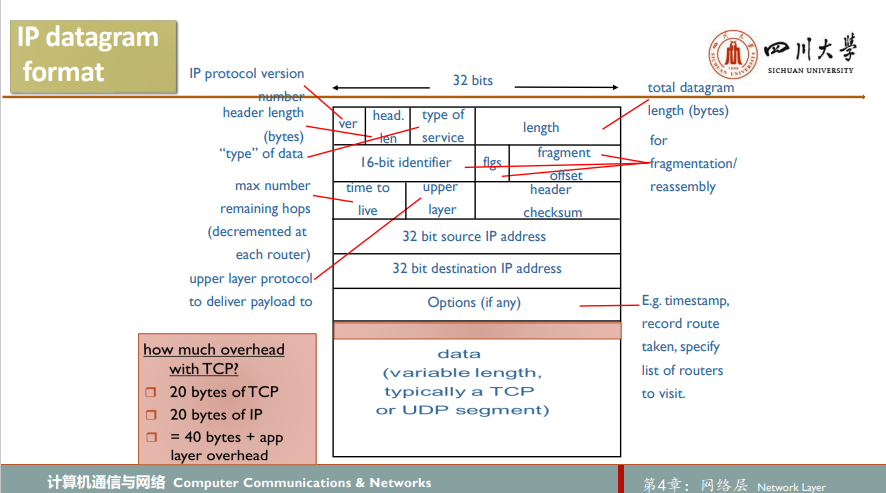
一个链路层帧能承载的最大数据量叫作被叫作最大传送单元Maximum Transmission Unit, MTU。如果IP数据报过大,将其分片为多个较小的IP数据报,用单独的链路层帧封装这些较小的IP数据报,然后通过输出链路发送这些帧。每个这些较小的数据报都称为片fragment
分片后,并不是从该路由器发往下一个路由器又重新组装,而是待所有的片到达端系统后再组装
一台主机通常只有一条链路连接到网络,当一台主机中的IP想要发送一个数据报时,它就在该链路上发送。主机和物理链路之间的边界叫作接口interface。现在考虑一台路由器及其接口。因为路由器的任务是从链路上接收数据报并从某些其他链路转发出去,路由器必须拥有两条或者更多链路与它连接。路由器与它的任意一条链路之间的边界也叫作接口。一台路由器因此有多个接口,每个接口有其链路。因为每台主机与路由器都能发送和接收IP数据报,IP要求每台主机和路由器接口拥有自己的IP地址。因此,从技术上讲,一个IP地址与一个接口相关联,而不是与包括该接口的主机或路由器相关联
因特网的地址分配策略被称为无类别域间路由选择Classless Interdomain Routing, CIDR。形式为a.b.c.d/x的地址的x最高比特构成了IP地址的网络部分,并且经常被称为该地址的前缀prefix(或网络前缀)。一个地址的剩余32 - x比特可认为是用于区分该组织内部设备的,其中的所有设备具有相同的网络前缀。当该组织内部的路由器转发分组时,才会考虑这些比特。也就是说,当该组织外部的一台路由器转发一个数据报,且该数据报的目的地址位于该组织内部时,仅需要考虑该地址的前x比特。这相当大程度地减少了在这些路由器中转发表的长度
几个接口通过一个并不包含路由器的网络互连起来,形成一个子网subnet。例如IP编制为某子网分配一个地址223.1.1.0/24,其中/24计法有时称为子网掩码network mask,指示32比特中最左侧的24比特定义了子网地址
IP广播地址为255.255.255.255。当一台主机发送一个目的地址为255.255.255.255的数据报时,该报文会交付给同一个网络中的所有主机。路由器也会有选择地向领近的子网转发该报文(虽然它们通常不这样做)
某组织一旦获得了一块地址,它就可为本组织内的主机与路由器接口逐个分配IP地址。主机地址也能手动配置,但这项任务目前更多的是使用动态主机配置协议Dynamic Host Configuration, DHCP来完成。DHCP允许主机自动获取一个IP地址,或分配某主机一个临时IP地址temporary IP address。除了分配主机IP地址外,DHCP还允许一台主机得知其他信息,例如它的子网掩码、它的第一跳路由器网址(常称为默认网关)与它的本地DNS服务器的地址
由于DHCP具有将主机连接进一个网络的网络相关方面的自动能力,故它又常被称为即插即用协议plug-and-play protocol或零配置协议zeroconf
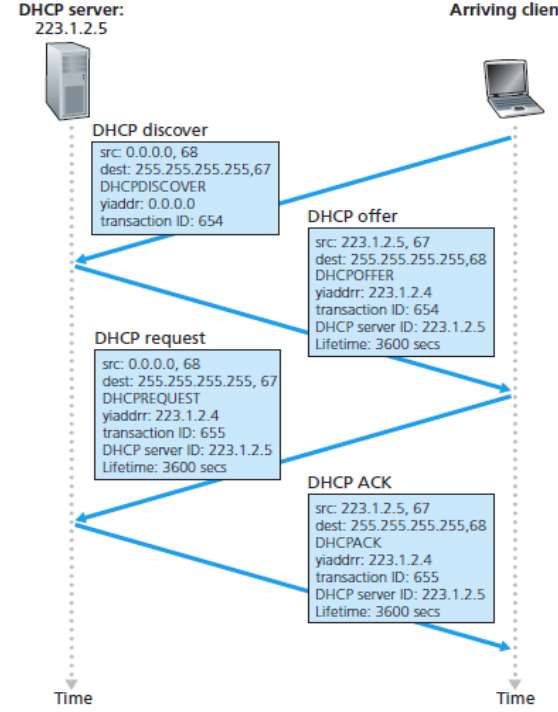
DHCP四个步骤的过程:
1)DHCP服务器发现。一台新到达的主机的首要任务是发现一个要与其交互的DHCP服务器。这可通过使用DHCP发现报文DHCP discover message来完成,客户在UDP分组向端口67发送该发送报文,使用广播目的地址255.255.255.255并使用“本主机”源IP地址0.0.0.0。DHCP客户将该IP地址传递给链路层,链路层然后将该帧广播到所有与该子网连接的节点
2)DHCP服务器提供。DHCP服务器收到一个DHCP发现报文时,用DHCP提供报文DHCP offer message向客户做出响应,该报文向该子网的所有节点广播,仍然使用IP广播地址255.255.255.255。因为子网中可能存在几个DHCP服务器,该用户可从几个提供者间进行选择。每台服务器提供的报文包含有收到的发现报文的事务ID、向客户推荐的IP地址、网络掩码以及IP地址租用期address lease time
3)DHCP请求。新到达的客户从一个或多个服务器中选择一个,并向选中的服务器提供用DHCP请求报文DHCP request message进行响应,回显配置的的参数
4)DHPC ACK。服务器用DHCP ACK报文DHCP ACK message对DHCP请求报文进行响应,证实所要求的参数
一旦客户收到DHCP ACK后,交互便完成了
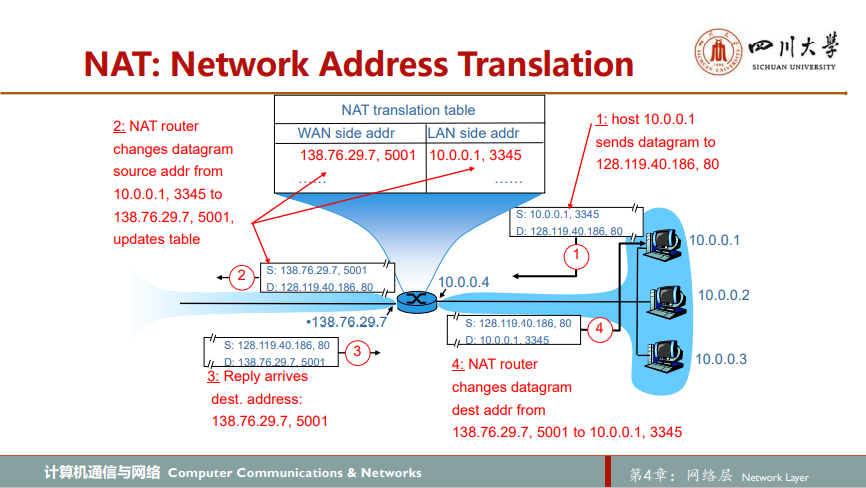
地址空间10.0.0.0/8是在[RFC 1918]中保留的三部分IP地址空间之一,这些地址用于家庭网络等专用网络private network或具有专用地址的地域realm with private address。具有专用地址的地域是指其地址仅对该网络中的设备有意义的网络。考虑有数十万家庭网络这样的事实,许多使用了相同地址空间10.0.0.0/24。在一个给定家庭网络中的设备能够使用10.0.0.0/24编址彼此发送分组。然而,转发到家庭网络之外进入更大的全球互联网的分组显然不能使用这些地址(或作为源地址,或作为目标地址),因为有数十万的网络使用着这块地址。这就是说,10.0.0.0/24地址仅在给定的网络中才有意义。但如果专用地址仅在给定的网络中才有意义的话,当向或从全球因特网发送或接收分组时如何处理编址问题呢,地址在何处才必须是唯一的呢?答案在于理解NAT
NAT使能路由器对于外界世界来说甚至不像一台路由器。相反NAT路由器对外界的行为就如同一个具有单一IP地址的单一设备。从本质上讲,NAT使能路由器对外界隐藏了家庭网络的细节。家庭网络计算机从何处得到其地址,路由器又是从何处得到它的单一IP地址呢?通常情况下,答案是相同的,即DHCP!路由器从ISP的DHCP服务器得到它的地址,并且路由器运行一个DHCP服务器,为位于NAT-DHCP路由器控制的家庭网络地址空间中的计算机提供地址
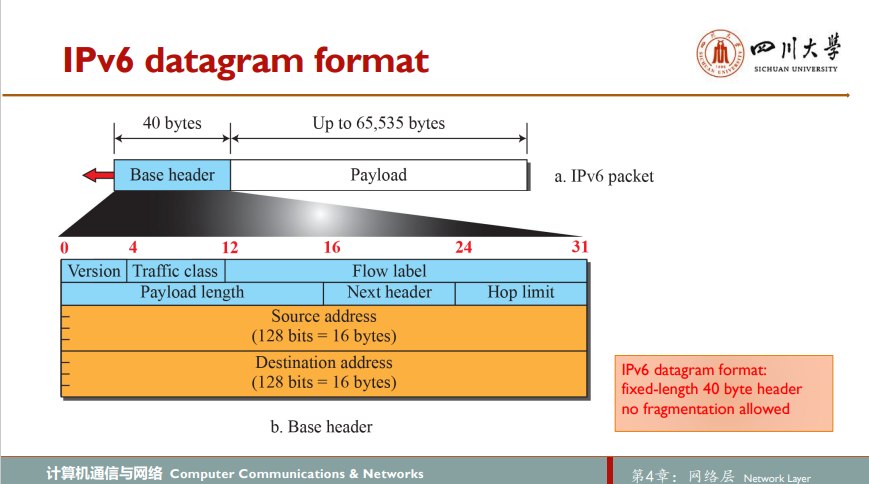
一个经常问的问题是:IPv5出了什么情况?人们最初预想ST-2协议将成为IPv5,但ST-2后来被舍弃了
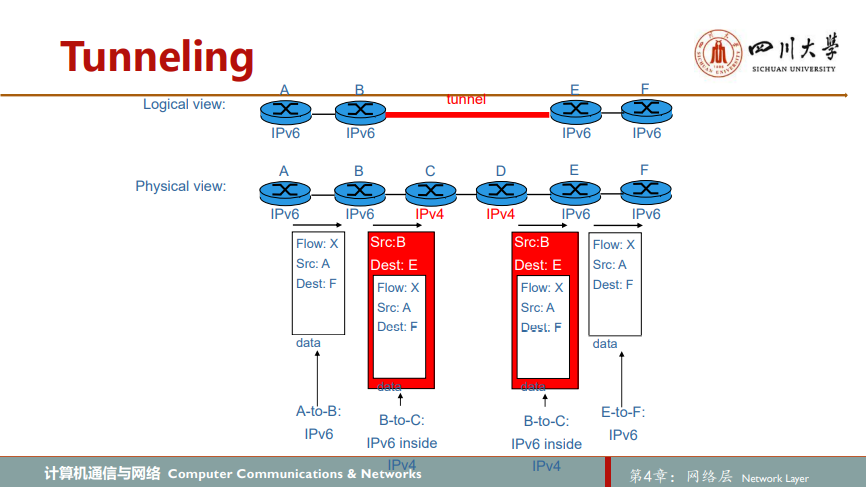
在实践中已经得到广泛采用的IPv4到IPv6迁移的方法包括建隧道tunneling。我们将两台IPv6路由器之间的中间IPv4路由器集合称为一个隧道tunnel。借助于隧道,在隧道发送端的IPv6节点可将整个IPv6数据报放到一个IPv4数据报的数据(有效载荷)字段中。于是,该IPv4数据报的地址设为指向隧道接收端的IPv6节点,再发送给隧道中的第一个节点。隧道中间的IPv4路由器在它们之间为该数据报提供路由,就像对待其他数据报一样,完全不知道该IPv4数据报自身就含有一个完整的IPv6数据报。隧道接收端的IPv6节点最终收到该IPv4数据报,从中取出IPv6数据报,然后再为该IPv6数据报提供路由,就好像它是从一个直接相连的IPv6邻居那里接收到该IPv6数据报的一样
路由选择算法routing algorithm的一种分类方式是根据该算法是集中式还是分散式来划分
集中路由选择算法centralized routing algorithm用完整的、全局性的网络知识计算出从源到目的地之间的最低开销路径。也就是说,该算法以所有节点之间的连通性及所有开销为输入,这就要求算法在真正开始计算前要以某种方式获得这些信息。具有全局状态信息的算法常被称作链路状态算法Link State, LS
在分散式路由选择算法decentralized routing algorithm中,路由器以迭代、分布式的方式计算出最低开销路径。没有节点拥有关于所有网络链路开销的完整信息。相反,每个节点仅有与其直接相连链路的开销知识即可开始工作,然后通过迭代计算过程以及与相邻节点的信息交换逐渐计算出到达目的节点或一组目的节点的最低开销路径。距离向量算法Distance-Vector, DV是分散式路由选择算法的一个例子
第二种广义分类方式是根据算法是静态的还是动态的进行分类。在静态路由选择算法·static routing algorithm中,路由随时间的变化非常缓慢,通常是人工进行调整。动态路由选择算法dynamic routing algorithm随着网络流量负载或拓扑发生变化而改变路由选择路径
第三种分类方式是根据它是负载敏感的还是负载迟钝的进行划分。在负载敏感算法load-sensitive algorithm中,链路开销会动态地变化以反映出底层链路的当前拥塞水平。如果当前拥塞的一条链路与高开销相联系,则路由选择算法趋向于绕开该拥塞链路来选择路由。当今因特网路由选择算法(如RIP、OSPF和BGP)都是负载迟钝的load-insensitive,因为某条链路的开销不明确地反映其当前(或最近)的拥塞水平
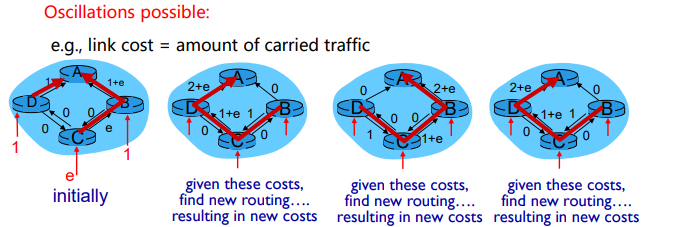
链路状态算法的一个具体例子就是Dijkstra算法,通过运行该算法,每台路由器都将知道从自己出发到任意目的点的最优解,但若该算法是拥塞敏感的,网络中的路由选择可能会振荡Oscillation
防止该振荡的一种解决方式是强制链路开销不依赖于所承载的流量,但这是一种不可接受的方案,因为路由选择的目标之一就是要避开高度拥塞的链路。另一种方案是确保并非所有的路由器都同时运行LS算法,因为我们希望即使路由器以相同周期运行LS算法,在每个节点上执行的时机也是不同的。有趣的是,研究发现因特网上的路由器能在它们之间进行自同步。这就是说,即使它们初始以同一周期但在不同时刻执行算法,算法执行时机最终会在路由器上变为同步并保持之。避免这种自同步的一种方法是,让每台路由器发送链路通告的时间随机化
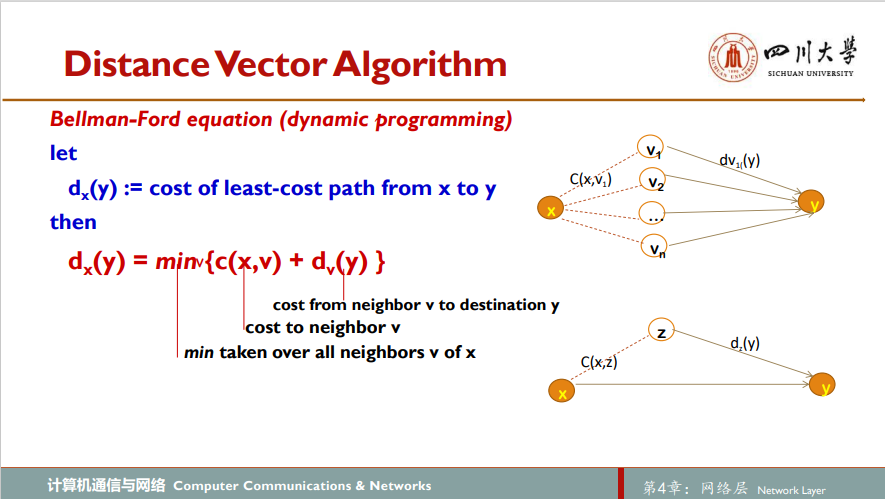
距离向量算法则是基于Bellman-Ford方程
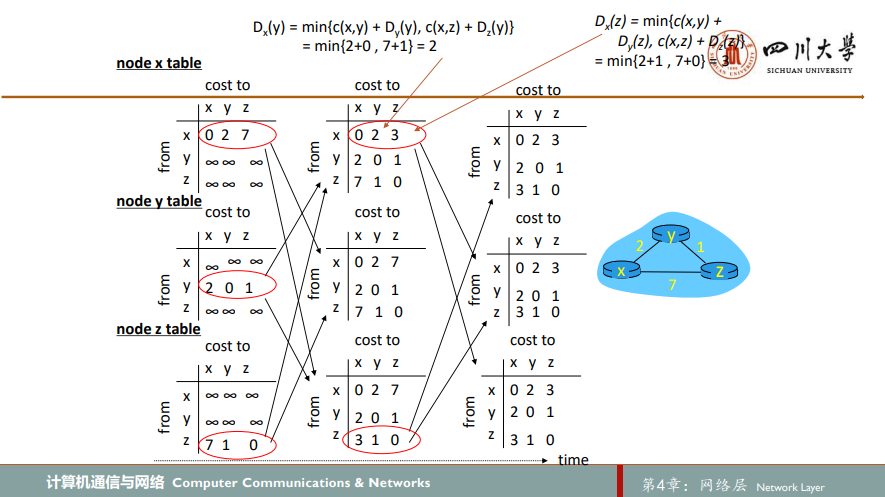
该算法存在缺陷:当两路由器间链路开销发生变化(例如,开销增大)时,可能在网络中形成路由选择环路routing loop,如下图所示
原本y到x开销为4,z经y到x开销为5.当(x, y)间链路开销突增至60时,我们期待的正确结果是:z通过开销为50的链路直接到达x,而y也通过z到达x,总开销为51.但实际上,y查询它的转发表,发现z到x开销为5(其实z正是通过y到达x的,但y不知道),于是y将其到x的路径改为先从y到z,再从z到x,总开销为6。设想有一个分组传至y路由器,其目的地址为x,则y将该分组发向z,z又传回给y…如此循环往复
一种称为毒性逆转poisoned reverse的算法可以避免两个路由间可能的路由选择环路,其思想是,如果z是通过y到达x的,则z告诉y它到x的距离为无穷大,即使实际上并不是。如此一来,还是上图中的情形,当(x, y)间开销增至60时,y发现它直接到x开销为60,而若选择走z这条路开销则是无穷,它别无选择,只能是直接到达x。当y修改其转发表后将新的数据发往z,z此时发现通过y再到x还不如直达x划算,于是修改路由为直接到达x,z又将新的数据发往y,接着y发现通过z到x开销更小,于是转而选择通过z到x。这样,一切和我们期待的一致
但毒性逆转无法解决多个路由形成的环路
总之,LS算法与DV算法没有一个是明显的赢家,它们的确都在因特网中得到了应用
之前的学习中,我们将网络只看作一个互联路由器的集合。从所有路由器执行相同的路由选择算法计算穿越整个网络的路由选择路径的意义上来说,一台路由器很难同另一台路由器区分开来,在实践中,该模型和这种一组执行同样路由选择算法的同质路由器集合的观点有点简单化,有两个重要原因:
1)规模。随着路由器数目规模变得很大,涉及路由选择信息的通信、计算和存储开销将高得不可实现
2)管理自治。因特网是ISP的网络,其中每个ISP都有它自己的路由器网络。ISP通常希望按自己的意愿运行路由器(如在自己的网络中运行它所选择的某种路由选择算法),或对外部隐藏其网络的内部组织面貌。理想情况下,一个组织应当按照自己的愿望运行和管理其网络,还要能将其网络与其他外部网络连接起来
这两个问题都可以通过路由器组织进自治系统Autonomous System, AS来解决。在相同AS中的路由器都运行相同的路由选择算法并且有彼此的信息。在一个自治系统内运行的路由选择算法叫作自治内部路由选择协议intra-autonomous system routing protocol
开放最短路优先OSPF路由选择及其关系密切的协议IS-IS都广泛用于因特网的AS内部路由选择。ISPF中的开放open指路由选择协议规范是公众可用的,该协议使用洪泛链路状态信息和Dijkstra最低开销路径算法。使用OSPF,一台路由器构建了一幅关于整个自治系统的完整拓扑图,而各条链路开销是由网络管理员配置的。OSPF的优点包括:1)安全,2)多条相同开销的路径。当到达某目的地的多条路径具有相同的开销时,OSPF允许使用多条路径,3)对 单播和多播路由选择的综合支持,4)支持在单个AS中的层次结构
OSPF是一个AS内部路由选择协议,而不同AS之间需要通过自治系统间路由选择协议inter-autonomous system routing protocol进行协调。在因特网中,所有的AS运行相同的AS间路由选择协议,称为边界网关协议Broder Gateway Protocol, BGP,BGP十分重要,正是这个协议将因特网中数以千计的ISP黏合起来。BGP是一种分布式和异步协议
当路由器通过BGP连接通告前缀时,它在前缀中包含一些BGP属性 BGP attribute。用BGP术语来说,前缀及其属性称为路由route。两个较为重要的属性是AS-PATH和NEXT-HOP。AS-PATH属性包含了通告已经通过的AS的列表,该AS将其ASN加入AS-PATH中现有列表。BGP路由器还使用AS-PATH属性来检测和防止通告环路;特别是,如果一台路由器在路径列表中看到包含了它自己的AS,它将拒绝该通告;NEXT-HOP是AS-PATH起始路由接口的IP地址。对于从AS1通过AS2到x的路由“AS2 AS3 x“,其属性NEXT-HOP是路由2a左边接口的IP地址。注意到NEXT-HOP属性不属于AS1的某路由器的IP地址;然而,包含该IP地址的子网直接连接到AS1
作为一种AS间的路由选择协议,BGP为每台路由器提供了一种完成以下任务的手段:1)从邻居AS获得前缀的可达性信息。特别是,BGP允许每个子网向因特网的其余部分通知它的存在;2)确定到该前缀的“最好的”路由
对于每个AS,每台路由器要么是一台网关路由器gateway router,要么是一台内部路由器internel router
热土豆路由选择hot potato routing是一种较为简单的BGP路由选择算法。若一台路由器到达前缀x有两条BGP路由,使用热土豆路由选择,(从所有可能的路由中)选择的路由到开始该路由的NEXT-HOP路由器具有最小开销。假设开销定义为穿越的链路数,则该路由选择离它跳数最少的NEXT-HOP
在实践中,BGP使用了一种比热土豆路由选择算法更加复杂但却结合了其特点的算法,如果到相同的前缀有两条或多条路由,则顺序地调用下列消除规则直到余下一条路由:
1)路由被指派一个本地偏好local preference值作为其属性之一(除了AS-PATH和NEXT-HOP以外)。本地偏好属性的值是一种策略决定,它完全取决于该AS的网络管理员。具有最高本地偏好值的路由将会被选择
2)从余下的路由中(所有都具有相同的最高本地偏好值),将选择具有最短AS-PATH的路由。如果该规则是路由选择的唯一规则,则BGP将使用距离向量算法决定路径,其中距离测度使用AS跳数而不是路由器跳数
3)从余下的路由中(所有都具有相同的最高本地偏好值和相同的AS-PATH长度),使用热土豆选择,即选择具有最靠近NEXT-HOP路由器的路由
4)如果仍留下多条路由,该路由器使用BGP标识符来选择路由
教材用的英文第五版,我用的中文第七版,第七版后面还有一点内容,但我实在懒得打字了
为了透彻理解链路层以及它是如何与网络层关联的,我们考虑一个交通运输的类比例子。假设一个旅行计划为游客开辟从美国新泽西州的普林斯顿到瑞士洛桑的旅游路线。假定该旅行社认为对于游客而言最为便利的方案是:从普林斯顿乘豪华大轿车到JFK机场,然后乘飞机从JFK机场去日内瓦机场,最后乘火车从日内瓦机场到洛桑火车站。一旦该旅行社作了这3项预定,普林斯顿豪华大轿车公司将负责将游客从普林斯顿带到JFK,航空公司将负责将游客从JFK带到日内瓦,瑞士火车服务将负责将游客从日内瓦带到洛桑。该旅途中3段中的每一段都在两个“相邻”地点之间是“直达的”。注意到这3段运输是由不同的公司管理,使用了完全不同的运输方式(豪华大轿车、飞机和火车)。尽管运输方式不同,但它们都提供了将旅客从一个地点运输到相邻地点的基本服务。在这个运输类比中,一个游客好比一个数据报,每个运输区段好比一条链路,每种运输方式好比一种链路层协议,而该旅行社好比一个路由选择协议
链路层能够提供的可能服务包括:成帧framing;链路接入。媒体访问控制Medium Access Control, MAC协议规定了帧在链路上传输的规则;可靠交付;差错检测和纠正
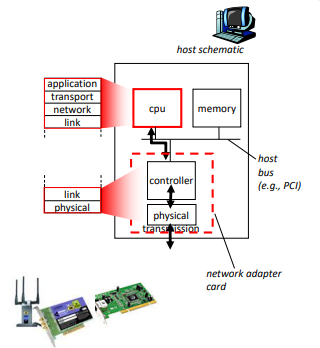
链路层的主体部分是在网络适配器network adapter中实现的,网络适配器有时也称为网络接口卡Network Interface Card, NIC。位于网络适配器核心的是链路层控制器,该控制器通常是一个实现了许多链路层服务(成帧、链路接入、差错检测等)的专用芯片
差错检测和纠正技术有:1)奇偶校验,包括使用单个奇偶检验位parity bit和二维奇偶校验two-dimensional parity;2)检验和方法;3)循环冗余检测Cyclic Redundancy Check, CRC编码
如何协调多个发送和接收节点对一个共享广播信道的访问,这就是多路访问问题multiple access problem,解决这个问题的协议即所谓多路访问协议multiple access protocol
因为所有节点都能传输帧,所以多个节点可能会同时传输帧。当发生这种情况时,所有节点同时接收到多个帧;这就是说,传输的帧在所有的接收方处碰撞collide了。涉及此次碰撞的所有帧都丢失了,在碰撞时间间隔中的广播信道被浪费了
多年来以实现几十种多路访问协议,其中任意一种都可划分为3种类型之一:信道划分协议channel partitioning protocol,随机接入协议random access protocol和轮流协议taking-turns protocol
在理想情况下,对于速率为R bps的广播信道,多路访问协议应该具有以下所希望的特性:
1)当且仅当一个节点发送数据时,该节点具有R bps的吞吐量;
2)当有M个节点发送数据时,每个节点吞吐量为R/M bps。这不必要求M个节点中的每一个节点总是有R/M的瞬时速率,而是每个节点在一些适当定义的时间间隔内应该有R/M的平均传输速率
3)协议是分散的,这就是说不会因为某主节点故障而使整个系统崩溃
4)协议是简单的,使实现不昂贵
时分多路复用TDM
频分多路复用FDM
码分多址Code Division Multiple Access, CDMA
时隙ALOHA
ALOHA
CSMA两个重要的规则:
1)说话之前先听。如果其他人正在说话,等到他们说完话为止。在网络领域中,这被称为载波侦听carrier sensing,即一个节点在传输前先听信道。如果来自另一个节点的帧正向信道上发送,节点则等待直到检测到一小段时间没有传输,然后开始传输
2)如果与他人同时开始说话,停止说话。在网络领域中,这被称为碰撞检测collision detection,即当一个传输节点在传输时一直在侦听此信道。如果它检测到另一个节点正在传输干扰帧,它就停止传输,在重复“侦听-当空闲时传输”循环之前等待一段随机时间
这两个规则包含在载波侦听多路访问Carrier Sense Multiple Access, CSMA和具有碰撞检测的CSMACSMA with Collision Detection, CSMA/CD协议族中

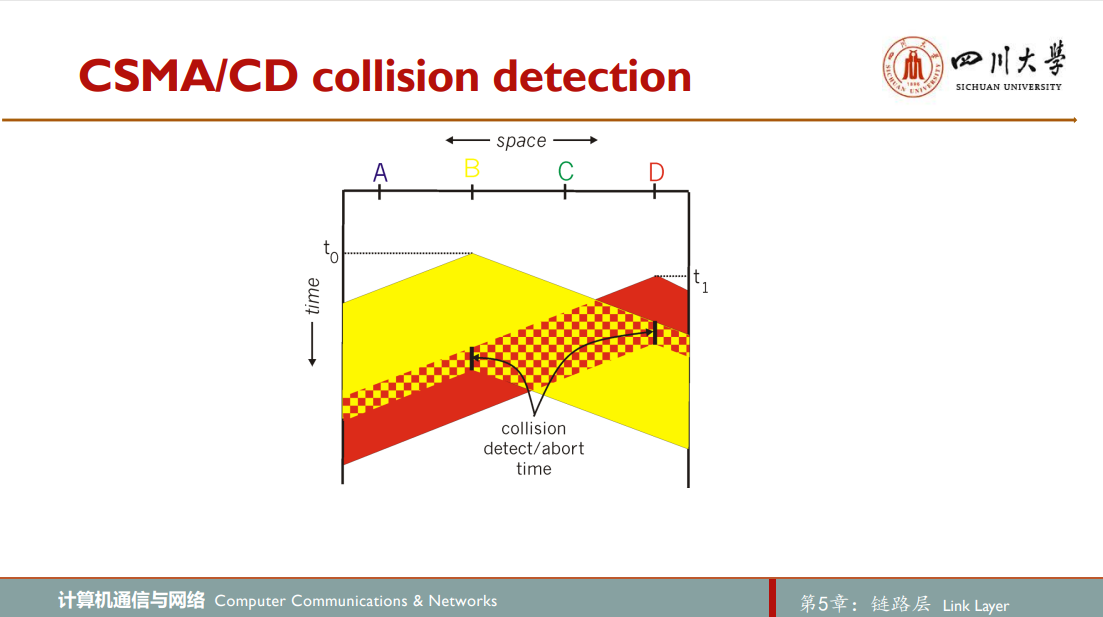
从图中可以看出,显然广播信道的端到端信道传播时延channel propagation delay(信号从一个节点传播到另一个节点所花费的时间)在决定其性能方面起着关键的作用。该传播时延越长,载波侦听节点不能侦听到网络中另一个节点已经开始传输的机会就越大。如果一个节点开始传播后发送碰撞,其实此次传播已经失败,将剩余数据传完没有意义,即使中止才是上策,这便是具有CSMA/CD所作改进
轮询协议polling protocol
令牌传递协议token-passing protocol
链路层地址有各种不同的称呼:LAN地址LAN address、物理地址physical address或MAC地址MAC address
适配器的MAC地址具有扁平结构(这与层次结构相反),而且不论适配器到哪里用都不会发送变化
因为存在网络层地址(例如,因特网的IP地址)和链路层地址(即MAC地址),所以需要在它们之间进行转换。对于因特网而言,这是地址解析协议Address Resolution Protocol, ARP
对路由器的每个接口,(在路由器中)也有一个ARP模块,一个IP地址
注意,链路层交换机是没有MAC地址的
交换机是自学习self-learning的,是即插即用设备plug-and-play device
剩下的感觉也不怎么考,杨老师的PPT做得太好了。。。甚至感觉我的笔记都没啥太大必要,直接看PPT就好。。。。
本博客中所有图片均来自杨频老师《计算机网络》PPT
特别感谢网安学院杨频教授授权我使用其PPT。杨老师的PPT重点突出且格式优美,对我对计算机网络的学习帮助巨大,再次感谢杨老师!
1 |
|
如果函数在class body内定义完成,便自动成为inline候选人
尽量使用initialization list初始化
一个变量数值的设定有两个阶段,初始化阶段和赋值阶段。initialization list是第一阶段设定,在花括号内用=符号赋值是第二阶段
1 | class Rectangle |
传引用,返回引用,如果可以的话
1 | inline complex& |
传递者无需知道接收者是以reference形式接收
总是应该考虑类的成员函数是否改变类的数据成员。若不改变,应显式地用const关键字限制函数行为
1 | class person |
如果指针是类的成员,则应仔细考虑拷贝构造函数,赋值函数和析构函数的编写,避免浅拷贝
1 | class String |
对于赋值运算符重载函数,一定要先检查是否自我赋值
1 | inline String& String::operator=(const String& str) |
就是说,用new关键词动态分配了一个数组,释放内存时一定得用delete []释放整个数组。如果没有加上中括号,可能会导致内存泄漏。
为什么只是可能?例如你动态分配N个某种类型的对象,它们是连在一起放在内存的某一块地方,负责管理的数据结构会记录这一块存的东西占了多大空间,存了多少个对象等等。所以当使用delete释放内存时,无论加不加中括号,N个对象的空间都会被回收,内存泄漏并不是发生在这里。试想,若这N个对象每个也都动态申请了内存,那么每个对象死亡时按理应该调用析构函数释放内存。如果使用delete[],编译器知道释放的是一个数组,编译器会分别调用这N个对象的析构函数,确保每个函数动态申请的空间都被释放掉,没有内存泄漏;但如果没有加上中括号,编译器以为释放的不是数组而只是一个元素,于是只会调用数组里第一个元素的析构函数,剩余元素的析构函数没有调用,它们所动态申请的空间也因此没有释放,导致了内存泄漏。
综上,如果动态申请一个对象数组,如果每个对象并没有动态申请空间,那么就算释放数组时忘记加中括号也不会有啥实际问题,但若每个对象单独又申请了空间,那么除了第一个元素外,剩余元素的动态申请的空间都没有回收,造成了泄漏
构造由内而外,析构由外而内
转换函数能将一种类型的对象转换为另一种类型的对象,试想,你编写了一个分数类(Fraction),该类成员变量为分子和分母,将该类的对象转换为一个浮点数用于算术运算是否是比较合乎情理的呢?于是,我们在类中添加operator double()转换函数,负责在需要时将该类的对象转换为double类型的对象
1 | class Fraction |
在编写如上转换函数后,我们可以将此类对象直接用于算数运算
1 | Fraction f(3.0, 5.0); |
当执行d = 4 + f语句时,编译器首先查看是否存在一个操作符重载函数,它的第一个参数是整数(或浮点数),第二个参数是Fraction类型的对象,没有这么个函数。于是又找是否存在转换函数,将Fraction类型的对象转换为double类型对象,找到了,于是调用该函数,将其转换为一个浮点值参与运算
需注意,operator double() const函数没有返回值
C++中既然存在上面提到的转换函数这种“把自己的类型对象转换为别的类型对象”的方法,也有“将其他类型对象转换为自己类型对象”的方法
1 | class Fraction |
首先观察该类的构造函数,有两个参数,但第二个有默认值,实际使用的时候可以只指明第一个参数值即可。可以说这个构造函数有两个parameter,而只有第一个参数是没有指明默认值的(non-explicit one argument)。再考虑d2 = f + 4;,f位于加号的左边,看起来有点满足Fraction类的加号重载函数,但是加号重载函数要求的参数是一个Fraction类的对象,而此时能作为参数的只有一个4,那能不能考虑将4从int类型转换为Fraction类型呢?整数4可以看作分数4/1,这符合我们的常识,编译器用Fraction类的构造函数,将4作为第一个参数,而第二个参数取默认值1,将原本int类的对象4转换为一个Fraction对象,于是加法得以进行
(以上解释是侯捷老师在课程中的解释,但说实话我还是不太明白编译器为啥就知道默默地去用构造函数来进行类型转换)
再看下述代码
1 | class Fraction |
这里main函数里的加法,将f转换为double类型对象也走得通,将数值4转换为Fraction类型对象也走得通,语句具有二义性,因此编译报错。但如果改变加法顺序
1 | Fraction d2 = 4 + f; |
分析知此情形只能是将f转换为double类型
explicit的意思是“清楚明白的,明确的,详述的;直截了当的,坦率的”。将其用于修饰构造函数,告诉编译器,“这个构造函数只能用于它的本职工作——在创建该类对象时进行初始化,别偷偷拿去搞什么类型转换的事情”。
1 | class Fraction |
加上explicit关键字后,由于参数类型不匹配,加号运算符重载这条路走不通了,因此f + 4唯一合理的解释就是将f通过转换函数转换为double类型的对象
以智能指针为例
1 | template<class T> |
智能指针用起来得像一个指针,所以得重载以上两个运算符。值得注意的是->运算符的重载,试想,若用户如此使用智能指针
1 | shared_ptr<Foo> sp(new Foo); |
实际上用户是想
1 | px->method(); |
但观察我们的->重载函数发现,重载函数已经将->运算符用掉了,让人产生疑惑。侯捷老师对此的解释是,->运算符很特别,它作用下去得到的结果会继续作用下去,因此该运算法能继续为px所用,上述的写法是行得通的
那不禁追问,为什么->运算符就恰好能行得通呢?答案是:语言是人创造的,语言的创造者想到了要这么用->运算符,就在底层实现了对如此使用的支持
说实话这一节学得并不很懂,一个仿函数的实例如下
1 | template <class T> |
使用它
1 | double d1 = 5; |
第一对括号是生成identity<double>类型的临时对象,第二对括号里是函数的参数。语句将d2的值设为5
1 | template <typename T> |
函数模板在使用时可以不指定类型(当然,指定也可以),编译器会自动进行实参推导argument deduction
1 | stone r1(2, 3), r2(1, 4), r3; |
一个模板内部又有模板,则里面嵌套这个就是成员模板。常用于构造函数
1 | template <class T1, class T2> |
试想这么一种情形:有两个基类,每个基类分别派生出一个派生类
1 | class Base1 {}; |
1 | pair<Derived1, Derived2> p; |
用对象p作为参数构造p2,p2调用的是成员模板的构造函数,可以这么做吗?用派生类对象给基类对象赋值?可以,这称为向上造型up-cast
特化与泛化整好相反,特化指定类型
1 | //这是泛化 |
关键词template后面接一对空的尖括号
函数名后加上一对尖括号,尖括号中指定需要特化的类型
有两种类型的偏特化
1)个数的偏
1 | //这是没有特化的模板 |
另一个例子
1 | //这是没有特化的模板 |
2)范围的偏
先看例子
1 | //没有特化 |
1 | C<string> obj1; |
使用时,若实际类型不是指针,则生成的是没有特化的类模板的对象obj1,若类型是指针,则生成的是范围特化了的类模板的对象obj2;注意,没特化的类模板和特化了的类模板看起来很像,但实际完全是两个东西,没啥关联
一句话,一个模板的参数又是一个模板
1 | template<typename T, template<typename T> class SmartPtr> |
使用
1 | XCls<string, shared_ptr> p1; |
注意到模板的参数和模板的参数模板的参数都是T。这样,当模板的第一个参数T确定时,参数模板的参数也随之确定,很自然就有SmartPtr<T>这样的用法
模板模板参数有什么用?见下面这个例子
1 | template<typename T, template<typename T>class Container> |
使用
1 | template<typename T> |
第一个参数决定存储数据类型,第二个参数决定用于存储的容器类型
看另一个例子
1 | template<class T, class Sequence = deque<T>> |
使用
1 | stack<int, list<int>> s; |
注意,这个例子不是模板模板参数,即其第二个参数不是模板。在使用stack时,第二个参数要显示指明list存储的对象类型,直接绑定死了,但之前例子里的模板模板参数在使用时第二个参数是不显式指定容器的参数类型的,而是在模板代码里绑定
1 | void print() {} |
使用
1 | print(7.5, "hello", false, 42); |
两点值得注意:1)typename...,Types&...以及args...,三个点是语法的一部分,表示数目不定(0个或多个),如果想知道可变参数的个数可使用sizeof...(args);2)注意到代码第一行有一个无参数的print()函数。当第四行有参数的print()不停递归调用自身时,每递归一次参数减少一个,当参数数目为零时不满足第四行的print()的调用要求(第四行这个函数要求至少有一个参数)。因此,若不写一个无参的print(),则编译出错
令我有点困惑的是在使用时不指明模板类型,而是直接传递函数参数调用函数,由函数参数类型自动倒推模板参数类型?虽然确实可以运行得到正确结果,还是不太明白背后的原理
实际上,引用底层是用指针实现的,但它给人一种假象,似乎它真就是引用对象的别名
定义一个对象int x = 0;,再用一个引用对象引用它int& rx = x;,对象和引用实际储存在内存里两个不同的位置,而且由于引用底层是指针实现的,理论上它的大小是该机器上指针大小(一半4字节或8字节),但对象的大小可大可小,没有限制。所以理论上对象和引用的大小可以不同,地址也不同。但是,当你使用
1 | sizeof(x) == sizeof(rx); |
进行比较判别是,会发现这两个判等表达式总是为真。故引用提供了一种假象,好似真的只是别名,让用户用起来十分便捷。引用的一个较大用处就是函数参数可以设置为传引用。的确,引用能实现的直接用指针也能实现,但用引用实现更加优雅
1 | void func1(Cls* pobj) { pobj->xxx(); } |
以上述代码为例,三个函数分别是传指针,传值和传参数。观察发现,传值和传引用接口相同,而传指针较为特别
需注意
1 | double imag(const double& im) { ... } |
此两函数的函数签名signature被视作相同,故不能同时存在
1 | double imag(const double im) const { ... } |
对于这两组函数中的一组,在函数名,参数表均相同的情况下,一个函数用const修饰,另一个没有,故其函数签名不一样,可同时存在。老实说为啥有无const能区分两个几乎一模一样的函数让我感到很疑惑,我也想不到合适的例子说服自己,但侯捷老师说它们不同,我也只好先保留疑惑
2021/12/5 更新:疑惑已解决,见”谈谈const“小节
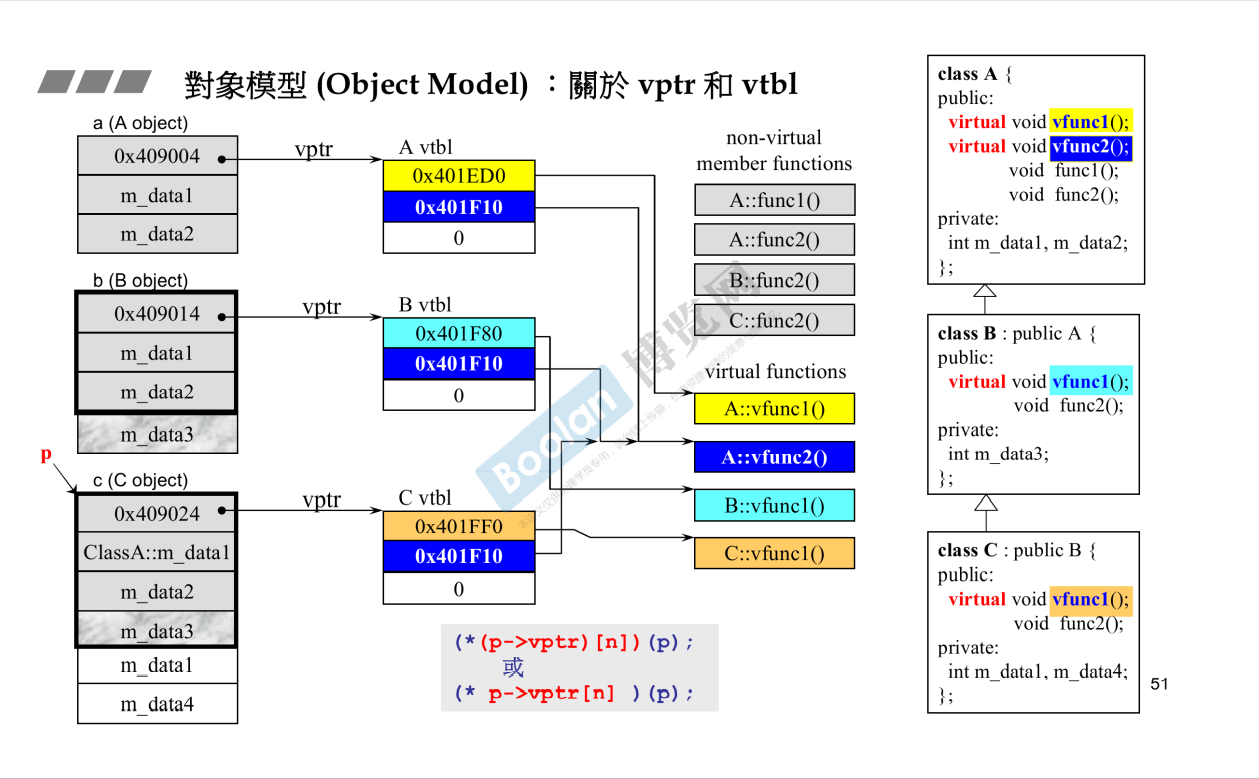
父类有虚函数,子类必然继承父类的虚函数。一个类有虚函数意味着什么呢?从内存的角度看,一个类有虚函数,意味着这个类存在一个虚指针virtual pointer,所以即使一个类除了虚函数其他啥数据也没有,用sizeof()去测这个类的对象的大小,会得到4或8,即一个指针的大小。虚指针指向一个虚函数表virtual table。虚函数表里是该类从父类那里继承而来的各个虚函数以及该类自己定义的新的虚函数(如果有的话)
注意,假设class A有两个虚函数func1(), func2(),class B继承自class A,而 class C又继承自class B。自然,这三个类都有自己的虚指针,但是三个类的指针指向的是三张不同的表。假如class B只重写了func1(),没有重写func2(),那么在class B的虚函数表里,一个表项指向的是原本class A的func2()的地址,另一个表项是指向一个新的、class B自己重写的func1()的地址。class B的func1()和class A的func1()是两个完全不同的函数。同理,若class C也是只重写了继承自class B的func1(),却没有重写func2(),则在class C的虚表中,一个表项指向class C自己的fun1()的地址,而另一个表项则是指向继承自class B的func2(),而class B的func2()其实也是从class A继承而来,因此,实际上class C的虚表的这个表项实际上最终是指向class A的func2()的地址。故在此例中,实际上只有四个虚函数:class A的func1(), func2(),class B的func2()和class C的func2()。三张不同的虚表,而每张虚表都有一个表项是指向class A的func2()的地址
我们可以用父类的指针指向子类的对象,因为子类对象是一个父类对象。例如有animal这个类,而它有dog这么个子类,dog当然是animal,因此可以按如下方式使用,称为up-cast
1 | vector<animal*> myVector; |
而animal不一定是dog,因此不能用dog类型的指针指向animal类型的对象
如果animal类有一个虚函数func1(),dog类重写了这个函数。当我们用animal类的指针指向dog类的对象,并通过这个指针调用func1()函数时,我们其实希望调用的是dog类的func1()函数,因此,编译器不能看到指针类型是animal就直接调用animal类型的func1(),而应分析指针指向的对象实际是什么类型,调用实际指向的对象类型的func1()。这称为动态绑定dynamic binding,传统C语言那种函数调用称为静态绑定static binding
注意,只有涉及指针时才考虑是否动态绑定,例如假设class A有虚函数func(),class B继承自class A,并且class B重写了func()
1 | B b; |
这不是用A类型的指针去指B类型对象,而是把B类型对象强制转换为A类型对象。因此,如果通过a去调用虚函数,调用的是A::func(),但如果
1 | B b; |
这种情况下,则调用的是B::func()
这一小节解决了之前遗留的一个疑惑:两个同名同参数的函数,一个用const修饰,一个没有,它们的函数签名是不一样的,即它俩可以并存,之前我就一直搞不懂那我调用时调用的是其中哪一个
注意,首先这里讨论的是类的成员函数,其次,上文所说的用const修饰是指
1 | class A |
而不是
1 | class A |
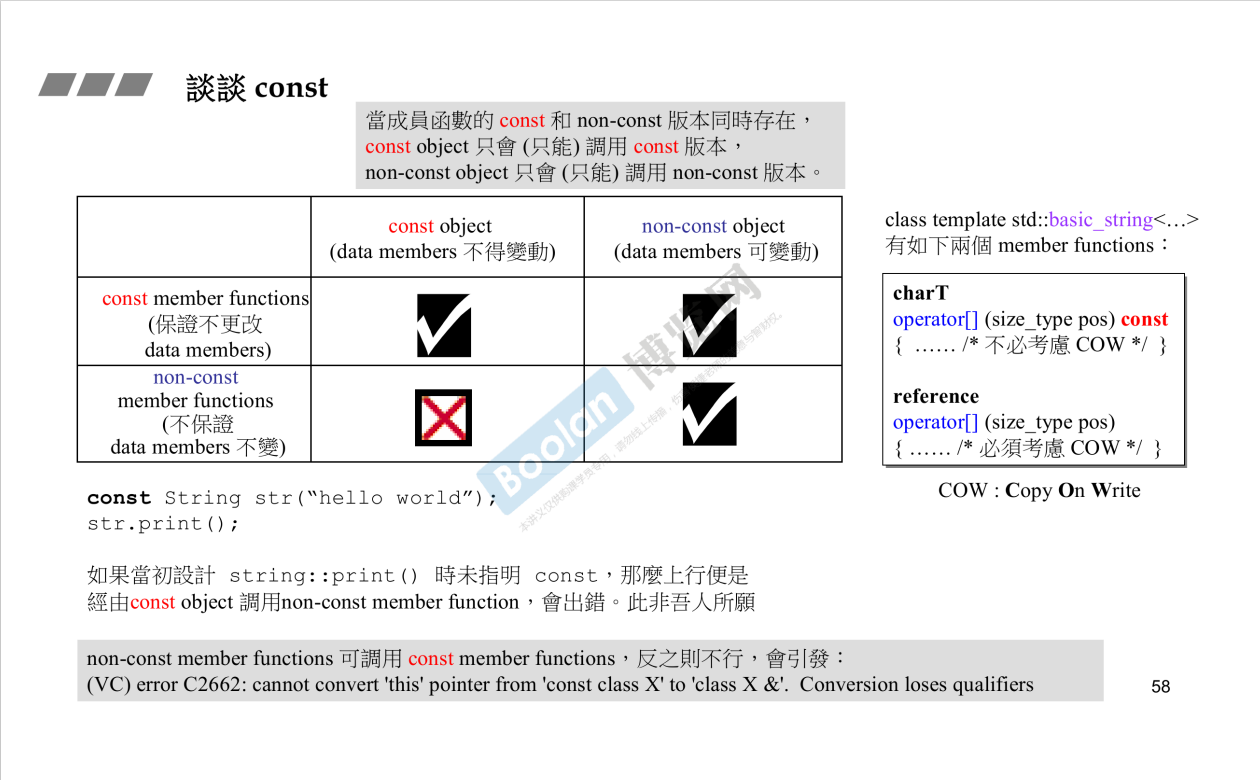
一个成员函数用const修饰代表它一定不会修改该类的成员变量,而不加const则说明它可能改变成员变量。因此用const修饰的成员变量只可能被同为const修饰的成员函数调用,而不可能被没const修饰的成员函数调用。但如果成员变量本身不是const修饰的,那无论成员函数是否有const修饰都可以调用它。这就存在我之前所产生的疑惑:当两个同名同参数函数同时存在,其中一个是const,另一个是非const,那么在调用时如何知道调用的究竟是哪个呢?
答案见图中上方小字:当两个版本的成员函数同时存在时,const object调用const版本的函数,non-const object调用non-const版本,这就解决了我的疑惑
这个知识点的用处何在呢?阅读上图右方的代码,basic_string是string底层的实现。我们可以有多个string对象,它们实际指向同一地址的字符串,以到达节约空间之效,而当某对象欲修改字符串内容时,为避免其行为影响到其他对象,因此必须进行写时复制。也就是说,平时通过[]运算符取字符串内容时,我们调用图右侧上方const版本的函数,而当通过该运算符修改字符串内容时,调用图右侧下方的non-const版本的函数,可在该函数中对字符串进行写时复制,避免错误发生
(本节图片均来自于侯捷老师课件)

初次接触operator new/delete, new handler, placement new/delete这些概念的时候是学习Effective C++时候,当时看得云里雾里的,根本不明白为什么一个new/delete操作要弄得这么复杂。今天(2022/4/18)看了侯捷老师的C++内存管理课程后,才终于对这些概念有一点感觉了。
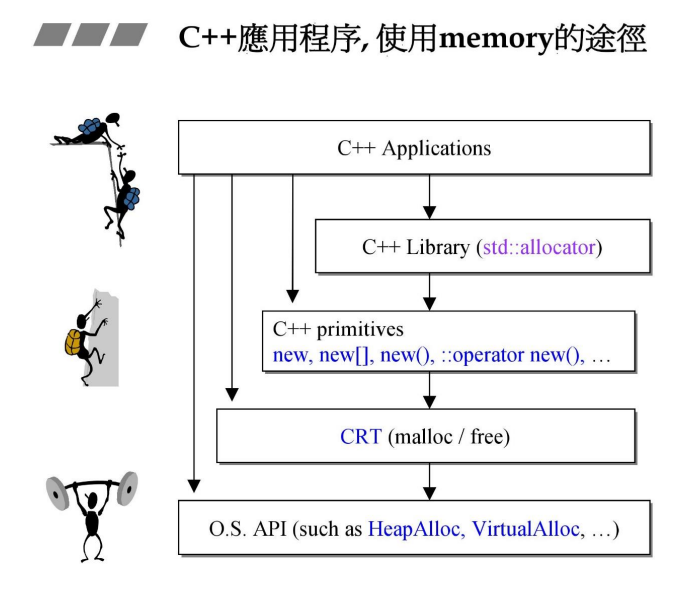
关于动态内存的申请与释放,C有malloc()和free()。malloc()需要一个size_t类型对象作为参数——你给它一个欲申请空间大小的值,它尝试在堆里找一块可用内存,将其首地址作为malloc()返回值返回。而当欲归还之前所申请的空间时,将指向欲归还内存的首地址的指针作为参数调用free()函数即可释放内存。
C++有new和delete,先说new。
1 | Complex *pc = new Complex(1, 2); |
上面这个new expression可以分解为以下三个步骤:
1 | void *p = operator new( sizeof(Complex) ); // allocate |
首先要在堆里申请一块内存,然后调用对象的构造函数进行构造。
申请内存实际由operator new()函数负责,其可能的逻辑如下:
1 | void* operator new(size_t size, const std::nothrow_t&) |
函数第二个参数const std::nothrow_t&指明:若尝试申请动态内存失败,该函数不抛出异常而是返回0.
每当我们尝试new一个对象的时候,我们实际做了两件事:申请对象需要的空间,然后调用构造函数进行对象的构造。申请内存由operator new()函数负责,(在标准实现中)该函数通过一个while循环不断地调用malloc()函数尝试申请所需的空间,若申请失败,则调用new_handler()函数进行处理,反复尝试直至申请内存成功或抛出异常。
我们发现,上述operator new()函数有不止一个参数,而我们一般情况下调用new时,只传给其一个参数:对象的大小。实际上,我们可以重载出多个不同的operator new()函数,它们只需要满足:
这便是placement new。有了placement new,还需要对应的placement delete。负责处理当对象构造失败时如何处理所申请的内存。
现在,假设放置对象所需的内存我们已经拿到了,接着就该调用构造函数进行对象构造,很遗憾,在构造过程中出现了错误,构造失败,于是我们处于这么一种境地:我们已经从堆中申请了内存,但由于构造对象失败,这片内存不能如我们预期所愿用来放置对象,换句话说,这片内存已经没用了。如果我们不能正确地将其释放,则会造成内存泄漏。如何归还该内存,便是placement delete的职责。
几个博弈论相关的游戏,挺有趣的,随手记录了
记录学习过程中遇到的各种知识点
APUE中文第三版习题解答